Articole recomandate
Generarea aranjamentelor
Citiți mai întâi Generarea permutărilor!
Introducere
Considerăm o mulțime cu n elemente. Prin aranjamente de k elemente din acea mulțime înțelegem șirurile de k elemente din ea. Două șiruri diferă prin valorile elementelor sau prin ordinea acestora.
Numărul acestor șiruri este aranjamente de n luate câte k, adică \(A_n^k = n \cdot (n-1) \cdot \ldots \cdot(n – k +1) \).
Acest articol prezintă algoritmul de generare în ordine lexicografică a aranjamentelor de k elemente ale mulțimii {1, 2, ..., n}. El poate fi ușor modificat pentru a genera aranjamentele unei mulțimi cu elemente oarecare.
Metoda folosită va fi backtracking, varianta recursivă. Deoarece în algoritmul de generare folosit intervine variabila k, ca parametru al funcției Back(), vom considera în continuare aranjamentele de n elemente luate câte p.
Exemplu
Pentru n = 4 și p = 3 vom avea 4 * 3 * 2 = 24 de aranajamente. Lista completă a acestora este:
1 2 3 2 1 3 3 1 2 4 1 2 1 2 4 2 1 4 3 1 4 4 1 3 1 3 2 2 3 1 3 2 1 4 2 1 1 3 4 2 3 4 3 2 4 4 2 3 1 4 2 2 4 1 3 4 1 4 3 1 1 4 3 2 4 3 3 4 2 4 3 2
Condiții
În rezolvarea problemei intervine vectorul soluție, x[]. Acesta reprezintă un aranjament candidat, care va deveni la un moment dat un aranjament de p elemente complet. Proprietățile vectorului soluție sunt cele specifice aranjamentelor:
- elementele sunt din mulțimea dată, adică numere intre
1șin; - elementele nu se repetă;
- vectorul se completează element cu element. Când va avea
pelemente, reprezintă un aranjament complet, care urmează a fi afișat.
Formal, exprimăm proprietățile de mai sus astfel:
- condiții externe: \( x[k] \in \left\{ 1,2, \ldots, n \right\} \);
- condiții interne: \(x[k] \notin \left\{ x[ 1 ],x[ 2 ], \ldots, x[ k-1 ] \right\}\), pentru \( k \in \left\{2,3, \ldots, n \right \} \)
- condiții de existență a soluției: \(k = p\)
Sursă C++
Următorul program afișează pe ecran aranjamantele de n alemente luate câte p, în ordine lexicografică, folosind un algoritm recursiv:
#include <iostream>
using namespace std;
int x[10] , n , p;
void Afis(int k)
{
for(int j = 1 ; j <= k ; j ++)
cout << x[j] << " ";
cout << endl;
}
bool OK(int k){
for(int i = 1 ; i < k ; ++ i)
if(x[k] == x[i])
return false;
return true;
}
bool Solutie(int k)
{
return k == p;
}
void Back(int k){
for(int i = 1 ; i <= n ; ++ i)
{
x[k] = i;
if(OK(k))
if(Solutie(k))
Afis(k);
else
Back(k + 1);
}
}
int main(){
cin >> n >> p;
Back(1);
return 0;
}
Se poate observa că atât condițiile descrise mai sus, cât și algoritmul de generare sunt foarte asemănătoare cu cele de la generarea permutărilor.
Acest lucru se datorează faptului că, la ambele probleme, vectorii soluție identici în ceea ce privește conținutul: șiruri de elemente diferite cuprinse între 1 și n. Diferă numai lungimea lor – momentul când vectorul soluție x[] conține o soluție completă:
- la problema permutărilor un vector soluție final are
nelemente (toate elementele mulțimii date, într-o anumită ordine); - la problema aranjamentelor un vector soluție final are
pelemente (pelemente dintre celenale mulțimii date, într-o anumită ordine).
La fel ca în cazul generării permutărilor, și pentru această problemă se pot scrie soluții iterative, precum și soluții în care verificarea condițiilor interne să se facă cu un vector caracteristic, evitându-se parcurgerile repetate ale vectorului soluție.
Probleme propuse
196 3159
Citește și
 Candale Silviu (silviu)
Candale Silviu (silviu) Polimorfism în C++
Generalități
Cuvântul polimorfism se referă la proprietatea unor substanțe, ființe, obiecte de a avea mai multe forme.
În contextul programării orientate pe obiecte, polimorfismul se referă la posibilitatea claselor de a avea mai multe metode cu același nume, dar cu efecte și rezultate diferite.
În C++ polimorfismul poate fi implementat prin:
- supraîncărcarea funcțiilor;
- supraîncărcarea operatorilor;
- suprascrierea funcțiilor;
- funcții virtuale.
Supraîncărcarea funcțiilor și operatorilor sunt tratate în acest articol: www.pbinfo.ro/articole/25851/supraincarcarea-functiilor-si-a-operatorilor.
Suprascrierea funcțiilor
Suprascrierea funcțiilor (overriding) se referă la situația ca într-o ierarhie de clase să avem metode cu același nume, dar cu efecte diferite. Considerăm clasele Animal și Caine.
#include<iostream>
using namespace std;
class Animal{
public:
void vorbeste()
{
cout << "Animalul vorbeste." << endl;
}
};
class Caine: public Animal{
public:
void vorbeste()
{
cout << "Cainele latra." << endl;
}
};
int main(){
Caine C;
Animal A;
C.vorbeste();
A.vorbeste();
C.Animal::vorbeste();
// A.Caine::vorbeste(); // imposibil
}
În exemplul anterior:
- clasa
Caineeste derivată din clasaAnimal; - obiectul
Ceste de tipCaine, obiectulAeste de tipAnimal; ambele sunt obiecte statice; - metoda
vorbeste()este disponibilă în ambele clase, fiind suprascrisă în clasa derivată - putem accesa corespunzător pentru fiecare obiect propria metoda
vorbeste() - pentru obiectul derivat putem accesa metoda clasei de bază folosind operatorul de rezoluție:
C.Animal::vorbeste();– invers nu este posibil!
Constatăm că pentru obiectele referite static accesarea metodelor suprascrise este rezolvată elegant, putând accesa orice metodă disponibilă în obiectul curent (proprie obiectului curent sau proprie aflate mai “sus” în ierarhie).
Suprascrierea în cazul pointerilor
Să vedem cum putem accesa membri claselor de bază/derivată în cazul pointerilor. Folosind clasele definite mai sus, considerăm următorul exemplu:
Caine C; Animal A; Animal * p; p = & A; p->vorbeste(); // Animalul vorbeste. p = & C; p->vorbeste(); // Animalul vorbeste. (?!?) Caine * q; q = & C; q->vorbeste(); // q = & A; // imposibil
Constatăm că:
- pointerul la clasa derivată (
q) poate memora doar adresa unui obiect al acesteia; - pointerul la clasa de bază (
p) poate memora atât adresa unui obiect al clasei de bază, cât și adresa unui obiect al clasei derivate; - chiar dacă pointerul memoreaza adresa unui obiect al clasei derivată, prin acel pointer se accesează metode ale clasei de bază!
Funcții virtuale
C++ oferă un mecanism prin care se alege metoda accesată printr-un pointer dinamic, la execuția programului, în funcție de clasa din care face obiectul referit de pointer (de bază sau derivată). Acest mecanism este reprezentat de funcțiile virtuale.
Declararea unei funcții (metode) virtuale este precedată de cuvântul C++ rezervat virtual în clasa de bază:
virtual tipRezultat metoda(parametri)
Exemplu:
#include<iostream>
using namespace std;
class Animal{
public:
virtual void vorbeste()
{
cout << "Animalul vorbeste." << endl;
}
};
class Caine: public Animal{
public:
void vorbeste()
{
cout << "Cainele latra." << endl;
}
};
int main(){
Caine C;
Animal A;
Animal * p;
p = & A;
p->vorbeste(); // Animalul vorbeste.
p = & C;
p->vorbeste(); // Cainele latra. (!)
}
Constatăm că:
peste declarat pointer la clasa de bază;ppoate memora fie adresa unui obiect din clasa de bază, fie adresa unui obiect din clasa derivată;- se apelează metoda corespunzătoare clasei din care face parte obiectul referit de pointer!
Înmulțirea a la russe și ridicarea la putere rapidă
Înmulțirea a la russe
Considerăm următorul algoritm, aplicat pentru două numere naturale a și b:
R ← 0 ┌ cattimp a ≠ 0 executa │ ┌ daca a este impar atunci │ │ R ← R + b │ └■ │ a ← [a / 2] │ b ← b * 2 └■ scrie R
Dacă îl vom aplica pentru a = 18 și b = 12 vom constata că:
a |
b |
R |
Explicație | ||
|---|---|---|---|---|---|
18 |
12 |
0 |
a este par => R nu se modificăa se înjumătățește, b se dublează |
||
9 |
24 |
0 + 24 = 24 |
a este impar => la R se adună b = 24a se înjumătățește, b se dublează |
||
4 |
48 |
24 |
a este par => R nu se modificăa se înjumătățește, b se dublează |
||
2 |
96 |
24 |
a este par => R nu se modificăa se înjumătățește, b se dublează |
||
1 |
192 |
24 + 192 = 216 |
a este impar=> la R se adună b = 192a se înjumătățește, b se dublează |
||
0 |
384 |
216 |
a a devenit 0, ne oprim |
||
Observăm că rezultatul R = 216 este de fapt chiar 18 * 12. Aceasta nu este o coincidență!
Algoritmul determină rezultatul înmulțirii dintre a și b și se numește înmulțirea a la russe (înmulțirea rusească). În ciuda numelui, se pare că metoda era cunoscută în Egiptul Antic și poate fi descrisă astfel:
- înmulțim numerele
așib:- dacă
aeste impar, il adunăm pebla rezultat, care inițial este0; ase înjumătățește, iarbse dublează;- continuăm pași 1 și 2 până când
adevine0.
- dacă
Aparent ciudată, metoda se bazează de fapt pe scrierea unui număr ca sumă de puteri ale lui 2 ( sau reprezentarea numerelor în baza 2) – știm că orice număr natural are o unică reprezentare în baza 2, poate fi scris în mod unic ca sumă de puteri ale lui 2.
Să-l scrie pe \(a = 18\) ca sumă de puteri ale lui 2: \(18 = 2 + 16 = 0 \cdot 2^0 + 1 \cdot 2^1 + 0 \cdot 2^2 + 0 \cdot 2^3 + 1 \cdot 2^4\). 0 1 0 0 1 sunt cifrele reprezentării lui 18 în baza 2, în ordine inversă (ordinea în care sunt determinate, prin metoda cunoscută ca resturi ale împărțirii la 2).
Atunci:
$$\begin{align}
18 \cdot 12 & = \left(0 \cdot 2^0 + 1 \cdot 2^1 + 0 \cdot 2^2 + 0 \cdot 2^3 + 1 \cdot 2^4 \right) \cdot 12 \\
& = \left(0 \cdot 1 + 1 \cdot 2 + 0 \cdot 4 + 0 \cdot 8 + 1 \cdot 16 \right) \cdot 12 \\
& = 0 \cdot 12 + 1 \cdot 24 + 0 \cdot 48 + 0 \cdot 96 + 1 \cdot 192 \\
& = 24 + 192 \\
& = 216 \\
\end{align}$$
Observăm deci că valorile care se adună pentru a obține rezultatul sunt tocmai acele valori obținute prin dublările succesive ale lui b când a este impar – ceea ce corespunde cifrei binare 1!!
Acest modalitate de înmulțire este interesantă, dar nu este neapărat utilă în practică. Mult mai interesant este următorul algoritm pentru ridicarea la putere, care poate fi utilizat în rezolvarea de probleme de informatică.
Ridicarea la putere rapidă
Să considerăm \(A^{25}\). Îl vom scrie pe \(25\) ca sumă de puteri ale lui \(2\): \(25 = 1 + 8 + 16\).
Atunci \( A^{25} = A^{1 + 8 + 16} = A^1 \cdot A^8 \cdot A^{16} = \underbrace{{(A^1)}^1}_{=A^1} \cdot \underbrace{{(A^2)}^0}_{=1} \cdot \underbrace{{(A^4)}^0}_{=1} \cdot \underbrace{{(A^8)}^1}_{=A^8} \cdot \underbrace{{(A^{16})}^1}_{=A^{16}}\). Observăm, desigur, că exponenții \(0\) și \(1\) sunt cifrele reprezentării în baza \(2\) a lui \(25\).
Pentru a determina An procedăm astfel:
- vom determina un produs
P, format din factori de formaA1,A2,A4,A8, … - determinăm cifrele reprezentării în baza
2a luin, începând cu cea mai nesemnificativă:- dacă cifra curentă este
1, înmulțim peAlaP,P ← P * A; - înmulțim pe
Acu el însuși,A ← A * A;, obținând următoarea putere din șirul de mai sus
- dacă cifra curentă este
Următorul program pseudocod descrie algoritmul de mai sus:
citeste A,n (baza, exponent) P ← 1 ┌ cattimp n ≠ 0 executa │ c ← n % 2 │ ┌ daca c = 1 atunci │ │ P ← P * A │ └■ │ n ← [n / 2] │ A ← A * A └■ scrie P
Observăm că algoritmul este foarte eficient! Numărul de iterații este egal cu numărul de cifre din reprezentarea în baza 2 a lui n – mult mai mic decât n!
Stars and bars
Stars and bars (Stele și bare) este o metodă de rezolvare a unor probleme de combinatorică. Se poate folosi când trebuie să determinăm numărul de modalități de a grupa un număr dat de obiecte identice.
Teoremă: Numărul de a variante de a plasa n obiecte identice în k cutii este egal cu: \( C_{n+k-1}^{k-1} \).
Demonstrația implică separarea celor n obiecte (stele) în k cutii prin k-1 bare – de unde și numele. De exemplu, configurația următoare are n=7 stele și k=4 cutii: \( \star \vert \star \star \vert \vert \star \star \star \star \) și corespunde următoarei situații:
- prima cutie conține un obiect
- a doua cutie conține două obiecte
- a treia cutie nu conține niciun obiect
- a patra cutie conține patru obiecte
Configurația este echivalentă cu următoarea configurație de biți: 0100110000, în care bitul 1 corespunde obiectului, \( \star \), iar 1 corespunde barei, \( \vert \). Toate configurațiile convenabile au n-k+1 biți, dintre care n au valoarea 0 și k-1 au valoarea 1 și corespund submulțimilor cu k-1 elemente ale unei mulțimi cu n+k-1 elemente.
Astfel, numărul lor este \( C_{n+k-1}^{k-1} \).
Consecință Ecuația \(x_1 + x_2 + x_3 + \cdots + x_k = n\) are \( C_{n+k-1}^{k-1} \) soluții întregi nenegative (mai mari sau egale cu 0).
Afirmația este echivalentă cu teorema de mai sus, în care \(x_i\) fiind egal cu numărul de obiecte din cutia i.
Teoremă: Numărul de a variante de a plasa n obiecte identice în k cutii astfel încât fiecare cutie conține cel puțin un obiect este egal cu: \( C_{n-1}^{k-1} \).
Demonstrația 1: Fixăm în fiecare cutie câte un obiect. Rămân \(n – k\) obiecte care trebuie plasate în \(k\) cutii, în condițiile teoremei de mai sus. Astfel, numărul de variante este \( C_{n-k+k-1}^{k-1} = C_{n-1}^{k-1} \).
Demonstrația 2: Folosim metoda Stars and bars. Separarea obiectelor în cutii se face plasând \(k\) bare în golurile dintre obiecte. Sunt \(n-1\) goluri în care putem plasa \(k\) bare în \( C_{n-1}^{k-1} \) moduri.
C++ STL bitset
bitset este un container special din STL care permite lucrul cu șiruri de biți. Aceștia sunt memorați eficient, pentru un bit din șir folosindu-se un bit în memorie. Astfel, spațiul de memorie ocupat de un bitset cu M biți este mai mic decât un tablou bool V[M]; sau un vector cu elemente de tip bool, dar numărul de biți M din bitset trebuie să fie cunoscut în momentul compilării, deci trebuie să fie o contantă.
Pot fi folosiți de exemplu pe post de vectori caracteristici, dar suportă și operațiile pe biți cunoscute pentru tipurile întregi.
Declararea
Pentru a folosi containerul bitset trebuie inclus headerul bitset:
#include <bitset>
Declararea se face astfel:
const int M = 16; bitset<M> B = 30;
Operații elementare
Afișarea
const int M = 16; bitset<M> B = 30; cout << B << endl;
Observații:
Meste constantă. Lipsa modificatoruluiconstduce la o eroare de compilare.- Când afișăm bitsetul, se afișează toți cei
Mbiți.
Indexarea
Biții din bitset sunt indexați de la 0 și pot fi accesați prin operatorul []. Bitul cel mai nesemnificativ (cel mai din dreapta) este B[0], iar bitul cel mai semnificativ este B[M-1], unde M este dimensiunea bitsetului.
const int M = 16; bitset<M> B = 30; // 0000000000011110 B[6] = 1; cout << B; // 0000000001011110
Compararea
Două containere bitset de aceeași dimensiune pot fi comparate cu operatorii == și !=.
Notă: operația != este eliminată în C++20.
Atribuirea
Putem să-i atribuim unui bitset valoarea unui întreg sau valoarea unui alt bitset. Prin atribuirea unui întreg, biții din bitsetul B devin identici cu biții din reprezentarea în memorie a valorii întregi care se atribuie:
const int M = 16; bitset<M> B, A; B = -30; cout << B << endl; // 1111111111100010 B = 5; cout << B << endl; // 0000000000000101 A = B; cout << A << endl; // 0000000000000101
Manipularea biților
Numărarea bitilor setați, numărul total de biți
Pentru a afle câți biți din bitset sunt setați (au valoarea 1), folosim metoda count(). Pentru a determina numărul total de biți, folosim metoda size(). Numărul biților nesetați (cu valoarea 0), facem diferența celor două.
const int M = 16; bitset<M> B = 63; cout << B.count() << endl; // 6 cout << B.size() << endl; // 16
Determinarea valorii unui bit
Se face cu metoda test(k), unde k reprezintă numărul de ordine al bitului dorit (de la dreapta spre stânga, incepând de la 0), iar rezultatul este 1 sau 0.
const int M = 16; bitset<M> B = 63; cout << B << endl; // 0000000000111111 cout << B.test(5) << endl; // 1 cout << B.test(6) << endl; // 0
Set, reset, flip
Bitsetul oferă metode pentru:
- setarea unui bit precizat:
B.set(k)dă valoarea1pentruB[k]B.set(k , r)dă valoarearpentruB[k]B.set()dă valoarea1pentru toți biții dinB
- resetarea unui bit precizat:
B.reset(k)dă valoarea0pentruB[k]B.reset()dă valoarea0pentru toți biții dinB
- schimbarea valoare biților (din
1devine0, iar din0devine1):B.flip(k)schimbă valoarea luiB[k]B.flip()schimbă valorile pentru toți biții dinB
bitset<M> B; B = 63; cout << B << endl; // 0000000000111111 //bitii se numeroteaza de la dreapta, incepand cu 0 B.reset(5); B.set(10); B.set(9 , 1); B.set(3 , 0); B.flip(2); cout << B << endl; // 0000011000010011 B.flip(); cout << B << endl; // 1111100111101100 B.set(); cout << B << endl; // 1111111111111111 B.reset(); cout << B << endl; // 0000000000000000
Operații pe biți
Operatii logice pe biți
Clasa bitset suportă operatorii logici pe biți (~, &, |, ^).
bitset<M> B, A; B = -60; A = 5; cout << "A = " << A << endl; // 0000000000000101 cout << "B = " << B << endl; // 1111111111000100 cout << "~B = " << ~B << endl; // 0000000000111011 cout << "A & B = " << (A & B) << endl; // 0000000000000100 cout << "A | B = " << (A | B) << endl; // 1111111111000101 cout << "A ^ B = " << (A ^ B) << endl; // 1111111111000001
Operatorii de deplasare
Clasa bitset suportă operatorii de deplasare a biților (<<, >>).
bitset<M> B; int n = 4; B = 7; cout << "B = " << B << endl; // 0000000000000111 cout << "B << n = " << (B << n) << endl; // 0000000001110000
Atribuiri
Clasa bitset suportă atriburile scurte: &=, |=, ^=, precum și <<=, >>=.
Fie A , B două containere bitset de aceași dimensiune și n un întreg. Atunci:
A &= Beste echivalent cuA = A & B;A |= Beste echivalent cuA = A | B;A ^= Beste echivalent cuA = A ^ B;A <<= neste echivalent cuA = A << n;A >>= neste echivalent cuA = A >> n;
Conversii
Bitset-ul poate fi convertit la
- string –
to_stringB.to_string()– returnează un string conținând reprezentarea binară a luiB, formată formată din caractere0și1;B.to_string(c0)– returnează un string conținând reprezentarea binară a luiB, caracterele0fiind înlocuite cu caracterulc0;B.to_string(c0 , c1)– returnează un string conținând reprezentarea binară a luiB, caracterele0și1fiind înlocuite cu caracterulc0, respectivc1;
- întreg fără semn-
to_ulong(),to_uulong()B.to_ulong()– retunează un întreg fără semn pe 32 de biți (unsingned int,unsigned long) cu reprezentarea binară echivalentă cu configurația bitsetuluiB;B.to_uulong()– retunează un întreg fără semn pe 64 de biți (unsigned long long) cu reprezentarea binară echivalentă cu configurația bitsetuluiB;- dacă valoarea întreagă corespunzătoare bitsetului nu poate fi reprezentată pe 32, respectiv 64 de biți, se va ridica o excepție de tip
overflow_error.
C++ vector - scurt tutorial
Containerul C++ vector este, probabil, cel mai folosit container STL. Vectorii sunt tablouri dinamice cu elemente omogene care au proprietatea de a se redimensiona automat când se adaugă sau se șterge un element, gestionarea memoriei fiind realizată automat de către container.
Vectorii sunt stocați într-o zonă contiguă de memorie și pot fi traversați cu ajutorul iteratorilor. Elementele se adaugă, de regulă la sfârșit. Operația de adăugare ia, de regulă, timp constant, cu excepția cazului când spatiul de memorie alocat trebuie redimensionat (mărit). Ștergerea unui element ia întotdeauna timp constant. Inserarea și ștergerea la începutul sau în interiorul vectorului iau timp liniar.
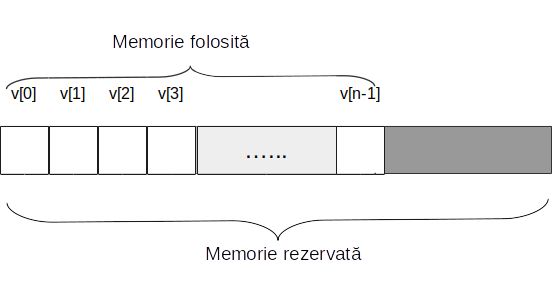
Declararea unui vector
Trebuie inclus header-ul vector:
#include <vector>;
Declararea se face astfel:
vector<T> V;
unde T este un tip de date. Acesta va fi tipul elementelor vectorului. Vectorul declarat mai sus este vid – are 0 elemente.
Alternativ, putem declara vectorul astfel:
vector<T> V(n);
n este un întreg. Se va crea un crea un vector V cu n elemente. Valorile acestora sunt valorile implicite pentru datele de tip T. Pentru tipurile numerice, valoarea elementelor este 0.
vector<T> V(n, vT);
n este un întreg, iar vT este o dată de tip T. Se va crea un crea un vector V cu n elemente. Valorile acestora sunt copii ale lui vT.
De exemplu:
vector<int> A; // se crează un vector A cu zero elemente cin >> n; vector<int> B(n); // se crează un vector B cu n elemente, egale cu 0 cin >> x; vector<int> C(n , x); // se crează un vector B cu n elemente, egale cu x
Atribuirea
Spre deosebire de tablourile standard C, vectorilor li se pot atribui valori în orice moment. Exemplu:
vector<int> A , B = {2 , 4, 6 , 8};
A = B;
A = {1 , 2 , 3 , 4 , 5};
Dimensiunea și capacitatea
Numărul de elemente din vector poate fi determinat cu funcția size():
vector<int> A = {2 , 4 , 6 , 8};
cout << A.size(); // 4
De regulă, memoria alocată pentru un vector este mai mare decât memoria folosită. Acest lucru se întâmplă pentru a se evita realocarea memoriei (operație costisitoare, care presupune copierea tuturor elementelor) de fiecare dată când se adaugă elemente.
Funcția capacity() returnează numărul de elemnte pe care le poate avea vectorul la momentul curent, fără a se realoca memoria. Are loc relația capacity() >= size(), iar numărul de elemente care pot fi adăugate fără realocare este capacity() - size().
Redimensionarea
Funcția resize() permite redimensionarea unui vector și are următoarele forme:
V.resize(n);(1)V.resize(n , x);(2)
Vectorul V se redimensionează încât să aibă n elemente:
- dacă
n < V.size(), în vector vor rămâne primelenelemente, celelalte vor fi șterse. - dacă
n > V.size(), în vector se vor adăugan - V.size()elemente egale cux, în cazul (2) sau egale cu valoarea implicită pentru tipul elementelor din vector, în cazul (1). Această valoare este0pentru tipurile numerice.
Adăugarea unui element
Adăugarea unui nou element în vector se face la sfârșit, cu funcția push_back():
vector<int> A; for(int i = 1 ; i <= 5 ; i ++) A.push_back(2 * i); cout << A.size();
Accesarea unui element
Elementele vectorilor pot fi accesate prin intermediul indicilor, cu operatorul []. Acesta nu verifică existență elementului cu un anumit indice, iar dacă acesta nu există, comportamentul programului este impredictibil.
vector<int> A; for(int i = 1 ; i <= 5 ; i ++) A.push_back(2 * i); for(int i = 0 ; i < A.size() ; i ++) cout << A[i] << ' '; // 0 2 4 6 8
De asemenea, este posibilă accesarea elementelor prin intermediul funcției at(). Aceasta returnează o referință la elementul de la poziția dată, iar dacă acesta nu există ridică o excepție care poate fi capturată prin mecanismul try … catch.
vector<int> A = {2 , 4 , 6 , 8 , 10};
A.at(1) = 20; //A = {2 , 20 , 6 , 8 , 10}
for(auto x : A)
cout << x << " ";
Primul și ultimul element poate fi accesat prin intemediul funcțiilor front() și back(). Ele returnează referințe la primul, respectiv ultimul element al vectorului. Comportamentul este impredictibil dacă vectorul este vid.
vector<int> A = {2 , 4 , 6 , 8 , 10};
A.at(1) = 20; //A = {2 , 20 , 6 , 8 , 10}
A.front() = 7; //A = {7 , 20 , 6 , 8 , 10}
A.back() = 5; //A = {7 , 20 , 6 , 8 , 5}
for(auto x : A)
cout << x << " ";
Iteratori
Iteratorii sunt similari cu pointerii. Cu ajutorul lor putem identifica adresa elementelor din vector. Iteratorii pot fi dereferențiați (obtinând referințe la elemente), pot fi incrementați/decrementați și pot fi adunați cu scalari.
Vectorii oferă prin intermediul funcției begin() un iterator la primul element al funcției, iar prin end() un iterator la elementul de după ultimul element al vectorului.
vector<int> A = {2 , 4 , 6 , 8 , 10};
vector<int>::iterator I;
for(I = A.begin() ; I < A.end() ; I ++)
cout << *I << " "; // 2 4 6 8 10
Observații:
- tipul variabilei iterator trebuie să fie în concordanță cu tipul elementelor vectorului;
- pentru a lucra cu elementul pentru care cunoaștem iteratorul, acesta trebuie să fie dereferențiat:
*I; - rezultatul funcției
A.end()este un iterator, dar acestuia nu-i corespunde un element al vectorului. Valoarea sa este adresa de după ultimul element al vectorului.
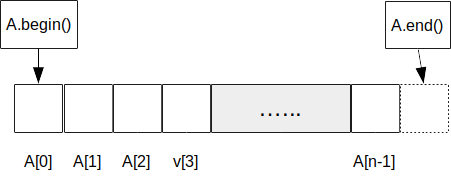
Clasa vector conține și funcțiile rbegin() și rend(), care returnează iteratori de tip reverse iterator, care permit parcurgerea vectorului în ordien inversă:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(vector<int>::reverse_iterator I = A.rbegin() ; I < A.rend() ; I ++)
cout << *I << " ";
Acești iteratori fac parte din categoria iteratorilor cu acces aleatoriu. Este cea mai puternică categorie de iteratori (cu cele mai multe operații definite). Aceste operații sunt:
| Expresie | Rezultat, efect |
|---|---|
*I |
Dereferențiere |
I->camp |
Acces la câmpurile structurii/membrii clasei memorate în elementele vectorului |
++I |
Preincrementare. Rezultatul este poziția următoare |
I++ |
Postincrementare. Rezultatul este poziția inițială |
--I |
Predecrementare. Rezultatul este poziția anterioară |
I-- |
Postdecrementare. Rezultatul este poziția inițială |
I == J |
Egalitate între doi iteratori |
I != J |
Neegalitate între doi iteratori |
<, >, <=, >= |
Operatori relaționali. Operanzii sunt iteratorii. Rezultatul este conform cu poziția în vector a elementelor adresate de cei doi iteratori |
I[k] |
Elementul de pe poziția k, începând de la I |
I += k |
k pași înainte |
I -= k |
k pași înapoi |
I + k |
iterator spre al k-lea element după cel curent |
I - k |
iterator spre al k-lea element înaintea celui curent |
I - J |
distanța în vector între iteratorii I și J |
Parcurgerea unui vector
O primă modalitate de parcurgere este folosind indicii, similar cu parcurgerea tablourilor standard C. Pentru determinarea numărului de elemnte există functia size():
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(int i = 0 ; i < A.size(); i ++)
cout << A[i] << " ";
De asemenea, putem folosi iteratorii:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(vector<int>::iterator I = A.begin() ; I < A.end() ; I ++)
cout << *I << " ";
Pentru ușurință, putem folosi specificatorul de tip auto pentru a stabili tipul iteratorului:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(auto I = A.begin() ; I < A.end() ; I ++)
cout << *I << " ";
Începând de la versiunea 2011 a standardului C++ există o formă specială a instrucțiunii for, care permite parcurgerea elementelor unui container:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(int x : A)
cout << x << " ";
Specificatorul de tip auto poate fi folosit și aici. În secvența de mai sus, x reprezintă pe rând câte o copie a elementelor din A. Eventualele modificări ale lui x nu vor modifica valorile elementelor din A. Dacă se dorește modificare elemenelor din A, atunci x trebuie să fie o referință:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(int & x : A)
x *= 2;
for(int x : A)
cout << x << " ";
Parcurgerea inversă
Vectorii suportă iteratori reversibili, care permit parcurgerea containerului în ordine inversă. Clasa vector are metodele:
rbegin()– returnează un iterator reversibil la ultimul element din containerrend()– returnează un iterator reversibil la elementul din fața primului
Parcurgerea se poate face astfel:
for(vector<int>::reverse_iterator I = V.rbegin() ; I < V.rend() ; I ++) cout << *I << " ";
Inserarea elementelor
Pentru adăugarea la sfârșit se folosește metoda push_back(). Pentru inserarea de noi elemente în interiorul containerului se folosește metoda insert(), care are mai multe forme:
V.insert(pos , x)– inserează în vectorulV, în fața iteratoruluiposun nou element cu valoareax;V.insert(pos , cnt , x)inserează în vectorulV, în fața iteratoruluipos,cntnoi elemente egale cux;V.insert(pos , st , dr)inserează în vectorulV, în fața iteratoruluipos,dr-stnoi elemente, având valorile egale cu cele ale elementelor din secvența[st, dr)dintr-un container oarecare. Dacă vectorulVși secvența[st,dr)se suprapun rezultatul este impredictibil.
Rezultatul apelurilor de mai sus este un iterator la primul element inserat.
Apelurile de mai sus invalidează toți iteratorii și referințele la elemente din V, dacă în urma inserării se realocă memorie, respectiv se invalidează iteratorii și referințele din dreapta lui pos, în caz contrar.
Mai multe detalii despre insert() aici: https://en.cppreference.com/w/cpp/container/vector/insert.
Eliminarea elementelor
Pentru eliminarea tuturor elementelor intr-un vector există metoda clear().
V.clear();
În urma eliminării, rezultatul lui V.size() este 0.
Pentru eliminarea ultimului element al tabloului există metoda pop_back(). În urma apelului se invalidează iteratorii și referințele la ultimul element, precum și iteratorul end().
Pentru eliminarea unor elemente oarecare se folosește metoda erase(), cu următoarele forme:
V.erase(pos)– elimină elementul indicat de iteratorulpos.posnu poate fi egal cuend()V.erase(st , dr)– elimină elementele din intervalul[st,dr), undestșidrsunt iteratori la elemente dinV
Rezultatul funcției erase() este un iterator la elementul de după ultimul element eliminat.
Se invalidează iteratorii și iteratorii din dreapta lui posm inclusiv iteratorul end().
Mai multe detalii aici: https://en.cppreference.com/w/cpp/container/vector/erase.
STL - Concepte fundamentale
Standard Template Library reprezintă un ansamblu de mecanisme scrise în C++ pentru gestionarea eficientă a unor colecții de date, împreună cu algoritmi eficienți care prelucrează aceste date. Este parte a Bibliotecii Standard C++, fiind astfel disponibilă în orice compilator care respectă standardul C++.
Introducere
STL are trei componente fundamentale: containerele, iteratorii și algoritmii, precum și o serie de componente suplimentare: containerele speciale, functorii, alocatorii.
Containerele
Containerele sunt obiecte care conțin date (de orice tip, putând fi la rândul containere). Alocarea memoriei pentru conținutul containerelor se face automat (de regulă dinamic), de către container.
Containerele sunt de două tipuri: containere secvențiale și containere asociative.
Containerele secvețiale gestionează un ansamblu de elemente dispuse strict liniar. Fiecare element al containerului are o poziție bine stabilită, care nu depinde de valoarea elementului. Avem următoarele contaniere secvențiale:
- vector – gestionează o secvență de elemente asemănătoare tablourilor standard C;
- deque (double-ended queue)- este o coadă cu operații rapide de adăugare și eliminare la ambele capete;
- list – gestionează o listă alocată dinamic, oferind operațiile de bază cu aceasta.
Timpul necesar pentru operațiile uzuale asupra containerelor secvențiale este redat mai jos:
| Operație | vector | deque | list |
|---|---|---|---|
| Accesarea primului element | constant | constant | constant |
| Accesarea ultimului element | constant | constant | constant |
| Accesarea unui element oarecare | constant | constant | liniar |
| Adăugare/ștergere la început | liniar | constant | constant |
| Adăugare/ștergere la sfârșit | constant | constant | constant |
| Adăugare/ștergere oarecare | liniar | liniar | constant |
Containerele asociative sunt structuri de date în care fiecare element are asociată o anumită cheie și are o anumită valoare. Ordinea elementelor în container depinde de cheie și se poate schimba în funcție de celelalte elemente. Aceste containere implementează eficient operațiile de adăugare de noi elemente, ștergere a elementelor în funcție de cheie, precum și căutarea elementelor după cheie.
Sunt două familii de containere asociative:
- set – în care cheia și valoarea elementelor sunt identice; containerele de acest tip sunt:
- set – memorează elemente distincte; elementele sunt menținute în ordine (strict) crescătoare;
- multiset – elementele pot fi egale și sunt menținute în ordine crescătoare;
- unordered_set – memorează elemente distincte; nu este garantată o anumită ordine a elementelor;
- unordered_multiset – elementele pot fi egale și nu este garantată o anumită ordine a elementelor
- map – cheile și valorile diferă; accesul la elemente se face prin intermediul cheii; containerele de acest tip sunt:
- map – cheile sunt distincte; elementele sunt menținute în ordine (strict) crescătoare a cheilor;
- multimap – cheile pot fi egale și sunt menținute în ordinea crescătoare a cheilor;
- unordered_map – cheile sunt distincte; nu este garantată o anumită ordine a elementelor;
- unordered_map – cheile pot fi egale și nu este garantată o anumită ordine a elementelor.
Timpii necesari pentru operațiile de adăugare, ștergere și acces sunt logaritmici pentru containerele asociative care menține elementele ordonate și constanți pentru containerele care nu mențin elementele în ordine.
Iteratorii
Iteratorii reprezintă o generalizare a conceputului de pointer. Ei oferă acces la elementele containerelor într-o manieră uniformă, pentru toate containere și pentru toți algoritmii STL.
Operațiile cu iteratorii sunt similare cu operațiile cu pointeri, putându-i dereferenția, incrementa/decrementa, compara, aduna cu întreg, etc. Unele operații sunt disponibile pentru toți iteratorii, altele doar pentru cei ai unor anumite tipuri de container.
Algoritmii
Algoritmii prelucrează colecții de elemente. Aceste colecții pot fi containere, părți ale unor containere sau slte structuri de date care permit lucrul cu pointeri (de exemplu tablouri standard C).
Algoritmii sunt folosiți sub formă de funcții, iar prelucrările pe care le fac sunt diverse: sortări, căutări, modificări, etc.
Containere speciale
Containerele speciale sunt:
- bitset – folosit pentru manipularea eficientă a șirurilor de biți
- containere adaptor – acoperă necesități speciale și sunt create pornind de la containere standard: containerele stack și queue permit gestionarea ușoară a unei stive, respectiv a unei cozi și sunt create pe baza containerului deque, iar containerul priority_queue gestionează o coadă de priorități (heap) și este creat pe baza clasei vector.
Functori și alocatori
Functorii sunt obiecte care se folosesc în maniera unui apel de funcție. Sunt folosite frecvent în cadrul algoritmilor.
Alocatorii sunt obiecte care gestionează alocarea memoriei pentru orice obiect și, în particular, pentru obiectele care fac parte dintr-un container.
Limbajul HTML - culori
În anumite situații trebuie să precizăm culori. Marcajele și atributele HTML care lucrează cu culori au devenit in mare măsură învechite și au fost înlocuite cu proprietăți CSS.
Așa cum știm, în calculator culorile sunt formate prin “amestecul” a trei culori de bază: red, green și blue. “Cantitatea” culorilor de bază variază între 0 și 255.
Culori în HTML
În HTML, culoarea poate fi precizată prin denumirea ei, (de exemplu red) sau prin codul ei hexazecimal (de exemplu #ff0000).
Codul hexazecimal este un șir de șase cifre hexazecimale (0, 1, .., 9, A, B, …, F), interpretate astfel:
- primele două cifre reprezintă cantitatea de red:
00reprezintă0, adică minim, iarFFreprezintă255, adică maxim; - următoarele două cifre reprezintă cantitatea de green
- ultimele două cifre reprezintă cantitatea de albastru
Sunt 16 culori cu denumire în HTML, deși este posibil ca browser-ele să recunoască mai multe denumiri de culoare:
black – #000000 |
silver – #C0C0C0 |
bgray – #808080 |
white – #FFFFFF |
||||
maroon – #800000 |
red – #FF0000 |
purple – #800080 |
fuchsia – #FF00FF |
||||
green – #008000 |
lime – #00FF00 |
olive – #808000 |
yellow – #FFFF00 |
||||
navy – #000080 |
blue – #0000FF |
teal – #008080 |
aqua – #00FFFF |
Culori în CSS
Cele mei multe atribute HTML care desemnează culori sunt învechite. Ele au fot înlocuite cu proprietăți CSS. Există mai multe proprietăți CSS care au ca valoare o culoare, de exemplu:
color– culoarea textului dintr-o casetăbackground-color– culoarea fundalului unei caseteborder-color– culoarea chenarului unei casete
Culorile pot fi precizate în CSS astfel:
- prin nume. Toate denumirile de culoare din HTML sunt disponibile în CSS. În plus, există multe alte denumire, disponibile aici: https://developer.mozilla.org/en-US/docs/Web/CSS/color_value.
- prin codul hexazecimal
#RRGGBB, cunoscut deja, sau prin codul hexazecimal extins#RRGGBBAA, undeAAreprezintă gradul de opacitate al culorii –00înseamnă complet transparent, iarFFînseamnă complet opac
<div style="background: url('wall-red.png'); padding:20px;">
<div style="background-color: #800080CC; color: teal; font-size: 2em; padding:20px; text-align: center;">
Culori
</div>
</div>
- prin codul hexazecimal scurt:
#RGBeste identic cu#RRGGBB#RGBAeste identic cu#RRGGBBAA
- folosind notația funcțională
rgb(r,g,b), under,gșibsunt numere (naturale scrise în baza10cu valori între0și255) sau procente (100%) corespunde cu255 - folosind notația funcțională
rgb(r,g,b,a), under,gșibsunt numere (naturale scrise în baza10cu valori între0și255) sau procente (100%) corespunde cu255.aeste un număr intre0(complet transparent) și1(complet opac) sau un procent (100%corespunde cu1); - folosind notația funcțională
hsl(h,s,l)sauhsl(h,s,l,a)– reprezentarea colorilor pe modelul HSL (hue, saturation, value). Detalii: https://en.wikipedia.org/wiki/HSL_and_HSV.
Limbajul HTML - legături și imagini
WWW (World Wide Web) a fost proiectat ca un set de resurse globale (pagini web, imagini, alte fișiere, etc.), stocate pe diverse servere și conectate la Internet. Fiecare resursă are o adresă unică la nivel global, numită adresă URL (Uniform Resource Locator), iar utilizatorul poate accesa aceste resurse prin intermediul browser-ului și poate naviga între ele foarte ușor folosind mouse-ul sau tastatura.
Legăturile sunt elemente dintr-o pagină web care fac posibilă navigarea între resursele internet. Legătura este o proprietate a unui bloc de text și/sau a unei imagine de a accepta comenzi prin intermediul mouse-ului sau a tastaturii. Aceste comenzi conduc de regulă la navigarea la o altă resursă web.
Elementul a
Pentru a crea o legătură, folosim elementul ancoră <a>...</a>. Acesta trebuie să aibă atributul href, care conține adresa URL a resursei asociate cu legătura, ea fiind absolută sau relativă și poate fi adresa oricărul tip de fișier: document html, imagine, etc. Între etichetele elementului <a> se scrie un text (sau un element imagine) care va fi afișat în pagina web și care va accepta comenzi de la mouse sau de la tastatură.
<a href="https://www.pbinfo.ro">pbinfo.ro</a>
Ancorele pot avea atributul target, prin care se precizează fereastra în care se va deschide resursa precizată prin href. Valoarea implicită este _self, reprezentând fereastra curentă (tab-ul curent). O altă valoare frecvent utilizată este _blank, cu înțelesul de fereatră nouă (tab nou). Mai multe detalii aici: https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a.
<a href="https://www.pbinfo.ro" target="_blank">pbinfo.ro</a>
Adrese relative și adrese absolute
O adresă absolută are următoarea formă:
protocol://nume.domeniu/cale/de/fisier.html
unde protocol este de regulă http sau https, nume.domeniu este numele de domeniu al site-ului în care este localizată resursa, /cale/de este calea spre directorul care conține fișierul resursă, iar fisier.html este fișierul propriu-zis. În acest fel fiecare resursă disponibilă în spațiul WWW este identificabilă.
Un site web reprezintă o colecție de fișiere localizate pe un server, într-un folder. Aceste fișiere pot fi documente html, imagini, fișiere de altă natură. De cele mai multe ori, crearea site-ului începe pe propriul calculator, fără a avea la dispoziție un server, deci fără ca fișierele din site să aibă o adresă URL validă. În acest context, în adresa URL lipsește partea protocol://nume.domeniu/, obținându-se o adresă relativă. Ea este relativă la structura de directoare care fac parte din folder-ul care conține site-ul și la documentul html din care face parte.
Considerăm următoarea structură de foldere și fișiere, în care site, pagini și img sunt foldere:
site --pagini ----pagina1.html ----pagina2.html --img ----poza1.jpg ----poza2.jpg --index.html
În fișierul index.html, următoarele adrese sunt corecte:
<a href="pagini/pagina1.html">Pagina 1</a> <a href="pagini/pagina2.html">Pagina 2</a> <a href="img/poza1.jpg">Poza 1</a> <a href="img/poza2.jpg">Poza 2</a>
Următoarele sunt greșite:
<a href="pagina1.html">Pagina 1</a> <a href="poza1.jpg">Poza 1</a> <a href="pagini/poza2.jpg">Poza 2</a>
În fișierul pagini/pagina1.html, următoarele adrese sunt corecte:
<a href="pagina2.html">Pagina 2</a> <a href="../index.html">Index</a> <a href="../img/poza1.jpg">Poza 1</a>
Ancore interne și externe
Legăturile de mai sus foloseau ancore externe – resursa destinație era în exteriorul documentului html curent. Putem defini și ancore interne, cu care putem naviga în interiorul paginii web curente.
Mecanismul este următorul:
- se stabilește destinația legăturii, folosind atributul
id:
<a id="destinatie"></a>
- se definește elementul
<a>:
<a href="#destinatie">Click</a>
Formatarea legăturilor cu CSS
<style>
#nav{
background-color: #ffff00;
list-style-type: none;
padding:0;
}
#nav li{display: inline;}
#nav li a{padding:5px; line-height: 20pt; text-decoration: none; background-color: #ff00ff; color: white; float:left; border-right: solid 1px white;}
#nav li a:hover{background-color: black; text-deoration: underline;}
</style>
<ul id="nav">
<li>
<a href="#">Link 1</a>
</li>
<li>
<a href="#">Link 2</a>
</li>
<li>
<a href="#">Link 3</a>
</li>
<li>
<a href="#">Link 4</a>
</li>
</ul>
Inserarea imaginilor
Imaginile îmbunătățesc semnificativ aspectul paginilor web. Pentru a insera o imagini, vom folosi elementul <img>.
<img src="santas.gif">
Adresa propriu-zisă a fișierului imagine se stabilește prin atributul src și este o adresă URL, absolută sau relativă. Acest atribut este practic obligatoriu. Un atribut recomandat este alt – alternative text, care conține un text care va fi afișat în cazul in care nu se poate afișa imaginea:
<img src="santas.gif" alt="Mos Craciun">
Alte atribute utile sunt height și width, care precizează înălțimea, respectiv lățimea, exprimate în pixeli, cu care se va afișa imaginea.
<img src="santas.gif" alt="Mos Craciun" width="100" height="200">
Mai multe informații despre elementul <img> sunt disponibile aici: https://developer.mozilla.org/en-US/docs/Web/HTML/Element/img.
Limbajul HTML - tabele
Tabelele permit afișarea informațiilor într-o formă organizată pe rânduri și coloane. Elementul <table> este unul dintre elementele HTML cu complexitate ridicată.
Orice tabel este compus din:
- un element
<table>...</table>– acesta conține toate celelalte elemente care definesc tabelul; - rânduri, definit prin elementul
<tr>– table row; - celule, definite prin elementul
<td>– table data, o celulă oarecare a tabelului sau<th>– care definește o celulă care este antet (header) pentru un grup de celule.
Un tabel implicit
În exemplul următor se afișează un tabel cu parametri impliciți.
<p> Un paragraf inaintea tabelului</p>
<table>
<tr>
<th>Nume</th>
<th>Prenume</th>
<th>Nota</th>
</tr>
<tr>
<td>Popescu</td>
<td>Ionel</td>
<td>7</td>
</tr>
<tr>
<td>Vlad</td>
<td>Gregoria</td>
<td>8</td>
</tr>
<tr>
<td>Lipan</td>
<td>Victoria</td>
<td>10</td>
</tr>
</table>
<p> Un paragraf dupa tabel.</p>
Un tabel formatat
Următorul tabel este formatat cu CSS:
<style>
table, td, th {border: solid 1px gray;}
table{ border-collapse: collapse; width: 100%;}
th{background-color:lightgray;}
tr:nth-child(even) td{color:red;}
</style>
<table>
<tr>
<th>Nume</th>
<th>Prenume</th>
<th>Nota</th>
</tr>
<tr>
<td>Popescu</td>
<td>Ionel</td>
<td>7</td>
</tr>
<tr>
<td>Vlad</td>
<td>Gregoria</td>
<td>8</td>
</tr>
<tr>
<td>Lipan</td>
<td>Victoria</td>
<td>10</td>
</tr>
</table>
Câteva elemente/atribute utile
Elementele care se folosesc pentru inserarea tabelelor au numeroase atribute. Aici discutăm o mică parte a lor. Pentru detalii consultați următoarele reurse:
- elementul
<table>– MDN - elementul
<tr>– MDN - elementul
<td>– MDN
Elementele thead, tbody, tfoot
Rândurile dintru tabel pot fi împărțite din punct de vedere semantic în trei categorii:
- rânduri antet ale tabelului – prin elementul
<thead> - rânduri care desemnează corpul tabelului – prin elementul
<tbody> - rânduri subsol ale tabelului – prin elementul
<tfoot>
Aceste elemente fac parte din elementul <table> și conțin zero sau mai multe rânduri (<tr>). Înțelesul lor este pur semantic, dar pot fi folosite și pentru formatarea CSS:
<style>
table, td, th {border: solid 1px gray;}
table{ border-collapse: collapse; width: 100%;}
thead tr{background-color: lightgray;}
tbody tr{background-color: #55CCFF;}
tfoot tr{background-color: #FFFF66;}
</style>
<table>
<thead>
<tr>
<th>Nume</th>
<th>Prenume</th>
<th>Nota</th>
</tr>
</thead>
<tbody>
<tr>
<td>Popescu</td>
<td>Ionel</td>
<td>7</td>
</tr>
<tr>
<td>Vlad</td>
<td>Gregoria</td>
<td>8</td>
</tr>
<tr>
<td>Lipan</td>
<td>Victoria</td>
<td>10</td>
</tr>
</tbody>
<tfoot>
<tr>
<td colspan="2">Media</td>
<td>8.33</td>
</tr>
</tfoot>
</table>
Atributele colspan și rowspan
o, Aceste atribute se aplică celulelor (<td> și <th>) și stabilesc pe câte rânduri se extinde celula (atributul rowspan), respectiv pe câte cloane se extinde celula (atributul colspan).
<style>
table, td{border: solid 1px gray;}
table{ border-collapse: collapse; width: 100%;}
</style>
<table>
<tr>
<td colspan="2"> 1 </td>
<td colspan="2"> 2 </td>
</tr>
<tr>
<td rowspan="2"> 1 </td>
<td rowspan="2" colspan="2"> 2 </td>
<td> 3 </td>
</tr>
<tr>
<td> 1 </td>
</tr>
<tr>
<td colspan="4"> 1 </td>
</tr>
</table>
Valorile implite ale atributelor rowspan și colspan sunt 1. Pentru colspan valorile mai mari decât 100 sunt considerate incorecte și redevin 1. Valorile rowspan egale cu 0 extind celula până la sfârșitul secțiunii de tabel din care face parte aceasta (secțiunile sunt definite de elementele <thead>, <tbody> și <tfoot>), iar valorile mai mari decât 65534 sunt reduse la 65534.
Alinierea celulelor
Conținutul unei celule (<td> sau <th>) poate fi aliniat pe orizontală și pe verticală. În acest scop putem folosi atributele align și valign, dar sunt învechite. Utilizarea lor nu este recomandată și se propune folosirea proprietăților CSS, astfel:
- alinierea pe orizontală se realizează prin intermediul proprietății CSS
text-align, cu valorileleft,right,centersaujustify; - alinierea pe verticală se realizează prin intermediul proprietății CSS
vertical-align, cu valorilebaseline,top,middlesaubottom;
<style>
table, td{border: solid 1px gray;}
td {padding:3px; text-align: center; height:100px;}
table{ border-collapse: separate; border-spacing: 3px;}
</style>
<table>
<tr>
<td style="text-align: left; width:120px;"> left </td>
<td style="text-align: center;"> center </td>
</tr>
<tr>
<td style="text-align: right;"> right </td>
<td style="text-align: justify;"> O propozitie mai lunga, care se va intinde pe mai multe linii. </td>
</tr>
</table>
<style>
table, td{border: solid 1px gray;}
td {padding:3px; height:100px;}
table{ border-collapse: separate; border-spacing: 3px; width: 100%;}
</style>
<table>
<tr>
<td style="vertical-align: baseline;"> baseline </td>
<td style="vertical-align: top;"> top </td>
<td style="vertical-align: middle;"> middle </td>
<td style="vertical-align: bottom;"> bottom </td>
</tr>
</table>