În unele situații se cere gruparea elementelor unei mulțimi date într-o colecție de submulțimi disjuncte. Pentru o astfel de colecție sunt importante următoarele operații:
- stabilirea submulțimii din care face parte un anumit element
- pentru două elemente date, reuniunea submulțimilor din care fac parte aceste elemente
Pentru fiecare submulțime se stabilește un reprezentant – unul dintre elementele submulțimii. Fiecare element al submulțimii este asociat într-un anumit mod cu reprezentantul acesteia. În acest fel, operația de stabilire a submulțimii din care face parte un anumit element constă în simpla identificare a reprezentantului, iar operația de reuniune a două submulțimii constă în asocierea elementelor unei submulțimii cu reprezentantul celeilalte. Două elemente fac parte din aceeași submulțime dacă sunt asociate cu același reprezentant.
Utilizări
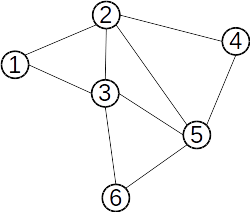
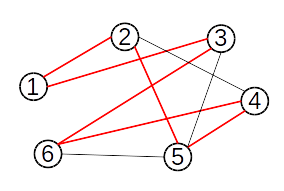
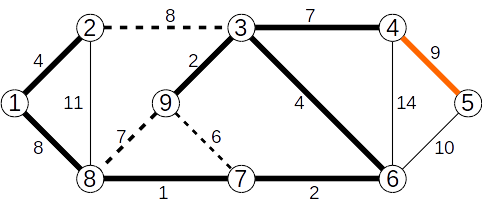
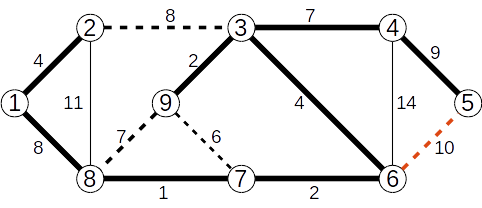
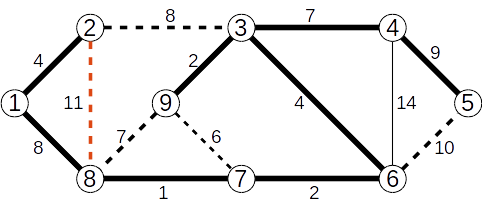
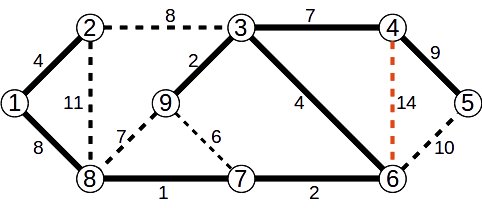
Operațiile cu mulțimi disjuncte pot fi folosite pentru determinarea componentelor conexe ale unui graf, astfel:
- inițial fiecare nod face parte din propria sa submulțime;
- pentru fiecare muchie
(x,y) stabilim dacă x și y fac parte din submulțimi diferite, caz în care reunim cele două submulțimi;
- la final, fiecare submulțime reprezintă câte o componentă conexă a grafului dat.
O altă aplicație a acestor structuri de date este Algoritmul lui Kruskal pentru determinarea arborelui parțial de cost minim a unui graf neorientat cu costuri.
Păduri de mulțimi disjuncte
O modalitate eficientă de gestionare a submulțimilor și a operațiilor cu acestea este utilizarea unor structuri arborescente (a unei păduri), numite pădure de mulțimi disjuncte, în care:
- fiecare submulțime este reprezentată printr-un arbore cu rădăcină
- rădăcina fiecărui arbore este reprezentantul submulțimii
- operațiile se implementează astfel:
- stabilirea submulțimii din care face parte un anumit element constă de regulă în identificarea rădăcinii arborelui din care face parte
- reuniunea a două submulțimi constă în concatenarea arborilor: rădăcina unuia dintre arbore i se stabilește devine tată pentru rădăcina celuilalt
Gestionarea arborilor se poate face prin intermediul unui vector de tați:
T[k] = 0, dacă k este rădăcină a unui arbore (și reprezentant al submulțimii corespunzătoare)T[k] = tatăl lui k în arborele din care face parte
Exemplu
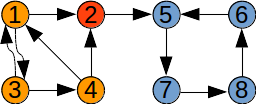
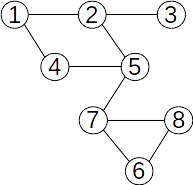
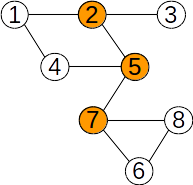
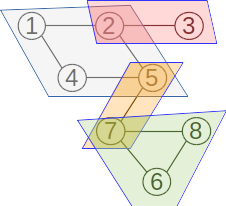
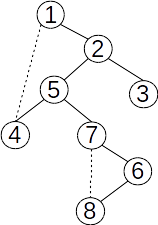
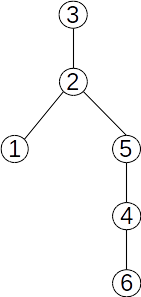
Fie mulțimea {1,2,3,4,5,6,7, 8} cu submulțimile disjuncte {1,3,4}, {2,5,7} și {6,8}. O reprezentare prin păduri de mulțimi disjuncte poate fi:
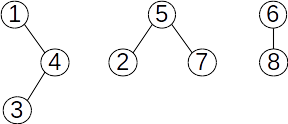
Ei îi corespunde următorul vector de tați:
k |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
T[k] |
0 |
5 |
4 |
1 |
0 |
0 |
5 |
6 |
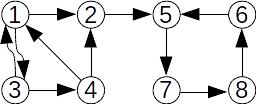
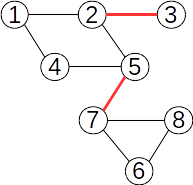
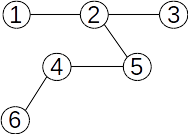
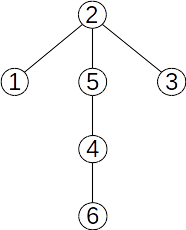
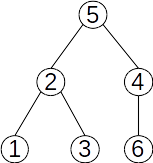
Dacă reunim submulțimile {2,5,7} și {6,8}, pădurea devine:
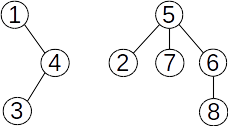
și îi corespunde următorul vector de tați:
k |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
T[k] |
0 |
5 |
4 |
1 |
0 |
5 |
5 |
6 |
Ambele operații (stabilirea submulțimii din care face parte un anumit element și reuniunea a două submulțimi) presupun identificarea reprezentantului unei submulțimii, adică a rădăcinii arborelui asociat submulțimii, operație ce presupune parcurgerea arborelui de la un nod spre rădăcină.
Implementare C++
Următoarea secvență C++ gestionează vectorul de tați T[], declarat global, prin intermediul a două funcții: int Radacina(int k), care determină rădăcina arborelui din care face parte nodul k (reprezentantul lui k) și void Unire(int k, int p), care realizează operația de reuniune a submulțimilor din care face parte k și p.
int T[...];
int Radacina(int k){
if(T[k] == 0)
return k;
else
return Radacina(T[k]);
}
void Unire(int k, int p)
{
int rk = Radacina(k), rp = Radacina(p);
if(rk != rp)
T[rk] = rp;
}
Îmbunătățirea operațiilor
Această implementare a operațiilor poate conduce la arbori cu înălțime mare. Acest fapt are efect asupra operației de determinare a rădăcinii arborelui din care face parte un nod dat, care este cu atât mai rapidă cu cât lungimea lanțului de la nod la rădăcină este mai mică. În gestionarea pădurilor de mulțimi disjuncte se pot folosi două euristici care duc la complexitate aproape liniară în raport cu numărul total de operații:
- reuniunea după rang – se va păstra pentru fiecare arbore o aproximare a dimensiunii sale, numită rang. La reuniunea a doi arbori, cel cu rangul mai mic va deveni subarbore al celui cu rangul mai mare. Dacă cei doi arbori au același rang, rangul arborelui obținut va crește cu o unitate;
- comprimarea drumului – în funcția de determinare a rădăcinii pentru un nod dat, modificăm tații nodurilor de pe lanțul spre rădăcină, astfel încât acestea să devină fii ai rădăcinii. Altfel spus, legăm nodurile direct de rădăcină.
Următoarea secvență C++ îmbunătățește operațiile de mai sus cu ajutorul celor două euristici. Pentru determinarea rangurilor folosim un vector suplimentar, Rang[]:
int t[...];
int Radacina(int k){
if(T[k] == 0)
return k;
else
{
int x = Radacina(T[k]);
T[k] = x;
return x;
}
}
void Unire(int k, int p)
{
int rk = Radacina(k), rp = Radacina(p);
if(rk != rp)
{
if(Rang[rk] > Rang[rp])
T[rp] = rk;
else
{
T[rk] = rp;
if(Rang[rk] == Rang[rp])
Rang[rp] ++;
}
}
}
Bibliografie:
- Cormen T, Leiserson C., Rivest R., Introducere în algoritmi, Editura Libris, 2000
- Lucanu D., Craus M., Proiectarea algoritmilor, Editura Polirom, 2008
- Giumale C., Introducere în analiza algoritmilor, Editura Polirom, 2004
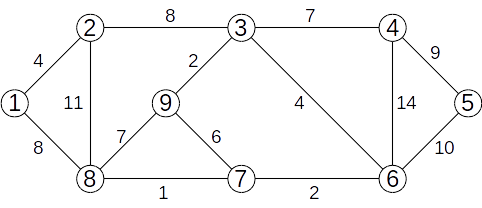
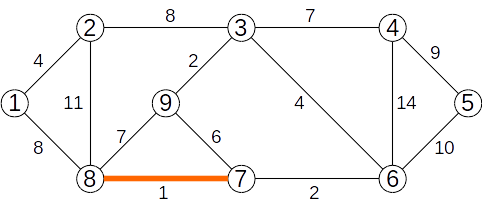
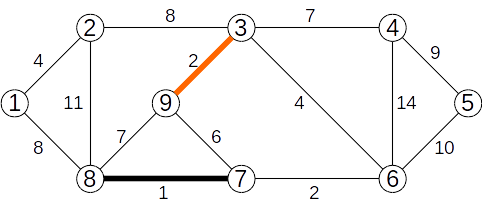
 Candale Silviu (silviu)
Candale Silviu (silviu)