Articole recomandate
Generarea aranjamentelor
Citiți mai întâi Generarea permutărilor!
Introducere
Considerăm o mulțime cu n elemente. Prin aranjamente de k elemente din acea mulțime înțelegem șirurile de k elemente din ea. Două șiruri diferă prin valorile elementelor sau prin ordinea acestora.
Numărul acestor șiruri este aranjamente de n luate câte k, adică \(A_n^k = n \cdot (n-1) \cdot \ldots \cdot(n – k +1) \).
Acest articol prezintă algoritmul de generare în ordine lexicografică a aranjamentelor de k elemente ale mulțimii {1, 2, ..., n}. El poate fi ușor modificat pentru a genera aranjamentele unei mulțimi cu elemente oarecare.
Metoda folosită va fi backtracking, varianta recursivă. Deoarece în algoritmul de generare folosit intervine variabila k, ca parametru al funcției Back(), vom considera în continuare aranjamentele de n elemente luate câte p.
Exemplu
Pentru n = 4 și p = 3 vom avea 4 * 3 * 2 = 24 de aranajamente. Lista completă a acestora este:
1 2 3 2 1 3 3 1 2 4 1 2 1 2 4 2 1 4 3 1 4 4 1 3 1 3 2 2 3 1 3 2 1 4 2 1 1 3 4 2 3 4 3 2 4 4 2 3 1 4 2 2 4 1 3 4 1 4 3 1 1 4 3 2 4 3 3 4 2 4 3 2
Condiții
În rezolvarea problemei intervine vectorul soluție, x[]. Acesta reprezintă un aranjament candidat, care va deveni la un moment dat un aranjament de p elemente complet. Proprietățile vectorului soluție sunt cele specifice aranjamentelor:
- elementele sunt din mulțimea dată, adică numere intre
1șin; - elementele nu se repetă;
- vectorul se completează element cu element. Când va avea
pelemente, reprezintă un aranjament complet, care urmează a fi afișat.
Formal, exprimăm proprietățile de mai sus astfel:
- condiții externe: \( x[k] \in \left\{ 1,2, \ldots, n \right\} \);
- condiții interne: \(x[k] \notin \left\{ x[ 1 ],x[ 2 ], \ldots, x[ k-1 ] \right\}\), pentru \( k \in \left\{2,3, \ldots, n \right \} \)
- condiții de existență a soluției: \(k = p\)
Sursă C++
Următorul program afișează pe ecran aranjamantele de n alemente luate câte p, în ordine lexicografică, folosind un algoritm recursiv:
#include <iostream>
using namespace std;
int x[10] , n , p;
void Afis(int k)
{
for(int j = 1 ; j <= k ; j ++)
cout << x[j] << " ";
cout << endl;
}
bool OK(int k){
for(int i = 1 ; i < k ; ++ i)
if(x[k] == x[i])
return false;
return true;
}
bool Solutie(int k)
{
return k == p;
}
void Back(int k){
for(int i = 1 ; i <= n ; ++ i)
{
x[k] = i;
if(OK(k))
if(Solutie(k))
Afis(k);
else
Back(k + 1);
}
}
int main(){
cin >> n >> p;
Back(1);
return 0;
}
Se poate observa că atât condițiile descrise mai sus, cât și algoritmul de generare sunt foarte asemănătoare cu cele de la generarea permutărilor.
Acest lucru se datorează faptului că, la ambele probleme, vectorii soluție identici în ceea ce privește conținutul: șiruri de elemente diferite cuprinse între 1 și n. Diferă numai lungimea lor – momentul când vectorul soluție x[] conține o soluție completă:
- la problema permutărilor un vector soluție final are
nelemente (toate elementele mulțimii date, într-o anumită ordine); - la problema aranjamentelor un vector soluție final are
pelemente (pelemente dintre celenale mulțimii date, într-o anumită ordine).
La fel ca în cazul generării permutărilor, și pentru această problemă se pot scrie soluții iterative, precum și soluții în care verificarea condițiilor interne să se facă cu un vector caracteristic, evitându-se parcurgerile repetate ale vectorului soluție.
Probleme propuse
196 3159
Citește și
 Candale Silviu (silviu)
Candale Silviu (silviu) Polimorfism în C++
Generalități
Cuvântul polimorfism se referă la proprietatea unor substanțe, ființe, obiecte de a avea mai multe forme.
În contextul programării orientate pe obiecte, polimorfismul se referă la posibilitatea claselor de a avea mai multe metode cu același nume, dar cu efecte și rezultate diferite.
În C++ polimorfismul poate fi implementat prin:
- supraîncărcarea funcțiilor;
- supraîncărcarea operatorilor;
- suprascrierea funcțiilor;
- funcții virtuale.
Supraîncărcarea funcțiilor și operatorilor sunt tratate în acest articol: www.pbinfo.ro/articole/25851/supraincarcarea-functiilor-si-a-operatorilor.
Suprascrierea funcțiilor
Suprascrierea funcțiilor (overriding) se referă la situația ca într-o ierarhie de clase să avem metode cu același nume, dar cu efecte diferite. Considerăm clasele Animal și Caine.
#include<iostream>
using namespace std;
class Animal{
public:
void vorbeste()
{
cout << "Animalul vorbeste." << endl;
}
};
class Caine: public Animal{
public:
void vorbeste()
{
cout << "Cainele latra." << endl;
}
};
int main(){
Caine C;
Animal A;
C.vorbeste();
A.vorbeste();
C.Animal::vorbeste();
// A.Caine::vorbeste(); // imposibil
}
În exemplul anterior:
- clasa
Caineeste derivată din clasaAnimal; - obiectul
Ceste de tipCaine, obiectulAeste de tipAnimal; ambele sunt obiecte statice; - metoda
vorbeste()este disponibilă în ambele clase, fiind suprascrisă în clasa derivată - putem accesa corespunzător pentru fiecare obiect propria metoda
vorbeste() - pentru obiectul derivat putem accesa metoda clasei de bază folosind operatorul de rezoluție:
C.Animal::vorbeste();– invers nu este posibil!
Constatăm că pentru obiectele referite static accesarea metodelor suprascrise este rezolvată elegant, putând accesa orice metodă disponibilă în obiectul curent (proprie obiectului curent sau proprie aflate mai “sus” în ierarhie).
Suprascrierea în cazul pointerilor
Să vedem cum putem accesa membri claselor de bază/derivată în cazul pointerilor. Folosind clasele definite mai sus, considerăm următorul exemplu:
Caine C; Animal A; Animal * p; p = & A; p->vorbeste(); // Animalul vorbeste. p = & C; p->vorbeste(); // Animalul vorbeste. (?!?) Caine * q; q = & C; q->vorbeste(); // q = & A; // imposibil
Constatăm că:
- pointerul la clasa derivată (
q) poate memora doar adresa unui obiect al acesteia; - pointerul la clasa de bază (
p) poate memora atât adresa unui obiect al clasei de bază, cât și adresa unui obiect al clasei derivate; - chiar dacă pointerul memoreaza adresa unui obiect al clasei derivată, prin acel pointer se accesează metode ale clasei de bază!
Funcții virtuale
C++ oferă un mecanism prin care se alege metoda accesată printr-un pointer dinamic, la execuția programului, în funcție de clasa din care face obiectul referit de pointer (de bază sau derivată). Acest mecanism este reprezentat de funcțiile virtuale.
Declararea unei funcții (metode) virtuale este precedată de cuvântul C++ rezervat virtual în clasa de bază:
virtual tipRezultat metoda(parametri)
Exemplu:
#include<iostream>
using namespace std;
class Animal{
public:
virtual void vorbeste()
{
cout << "Animalul vorbeste." << endl;
}
};
class Caine: public Animal{
public:
void vorbeste()
{
cout << "Cainele latra." << endl;
}
};
int main(){
Caine C;
Animal A;
Animal * p;
p = & A;
p->vorbeste(); // Animalul vorbeste.
p = & C;
p->vorbeste(); // Cainele latra. (!)
}
Constatăm că:
peste declarat pointer la clasa de bază;ppoate memora fie adresa unui obiect din clasa de bază, fie adresa unui obiect din clasa derivată;- se apelează metoda corespunzătoare clasei din care face parte obiectul referit de pointer!
Subșir crescător de lungime maximă
n elemente, numere naturale. Determinați un cel mai lung subșir crescător al șirului.
De exemplu, pentru n=10 și șirul A=(5, 10, 7, 4, 5, 8, 9, 8, 10, 2), cel mai lung subșir crescător va conține 5 elemente (5, 7, 8, 9, 10) sau (4, 5, 8, 9, 10).
Problema este una clasică și se rezolvă prin programare dinamică. Subșirul cerut se mai numește și subșir crescător maximal.
O soluție \(O(n^2)\)
Determinarea lungimii maxime
Pentru a determina lungimea maximă a unui subșir crescător al lui A, vom construi un șir suplimentar LG[], cu proprietatea că LG[i] este lungimea maximă a unui subșir care se începe în A[i]. Atunci lungimea maximă a unui subșir crescător va fi cel mai mare element din tabloul LG.
Vom construi șirul LG progresiv, începând de la ultimul element din A, bazându-ne pe următoarele observații:
LG[i] ≥ 1,∀iLG[n] = 1- vom determina
LG[i]astfel: analizăm toate elementeleA[j], cuj>iși îl alegem pe acela pentru careLG[j]este maxim șiA[i]≤A[j]. Fiejmaxindicele acestui element. AtunciLG[i]devineLG[i] = LG[jmax] + 1– elementulA[i]se lipește de subșirul care începe înA[jmax].
Secvență C++:
LG[n] = 1;
for(int i = n - 1 ; i > 0 ; i --)
{
LG[i] = 1;
for(int j = i + 1 ; j <= n; ++ j)
if(A[i] <= A[j] && LG[i] < LG[j] + 1)
LG[i] = LG[j] + 1;
}
După construirea șirului LG, lungimea subșirului maximal se determină ca fiind cea mai mare valoare din tabloul LG.
int pmax = 1;
for(int i = 2 ; i <= n ; i ++)
if(LG[i] > LG[pmax])
pmax = p;
cout << LG[pmax];
Reconstituirea subșirului
Există mai multe modalități de reconstituire a subșirului maximal. De asemenea, trebuie spus că pot exista mai multe șiruri maximale; în unele probleme poate fi determinat oricare, în altele trebuie determinat un subșir cu proprietăți suplimentare.
O soluție constă în construirea unui șir suplimentar, Next cu următoarea semnificație: Next[i] este următorul element în subșirul crescător maximal care începe cu A[i]. Dacă nu există un element următor, atunci LG[i] = -1. Acest tabloul se construiește în același timp cu LG, astfel:
LG[n] = 1, Next[n] = -1;
for(int i = n - 1 ; i > 0 ; i --)
{
LG[i] = 1 , Next[n] = -1;
for(int j = i + 1 ; j <= n; ++ j)
if(A[i] <= A[j] && LG[i] < LG[j] + 1)
LG[i] = LG[j] + 1, Next[i] = j;
}
Pentru a afișa subșirul, vom extrage informațiile necesare din șirul Next, pornind de la indicele pmax determinat mai sus:
int p = pmax;
do
{
cout << p << " ";
p = Next[p];
}
while(p != -1);
Putem reconstitui subșirul fără a construi șirul Next. La fiecare pas al structurii repetitive de mai sus vom determina un indice pUrm cu proprietatea că LG[pUrm]==LG[p]-1 și A[p] ≤ A[pUrm]:
int p = pmax;
do
{
cout << p << " ";
int pUrm = p + 1;
while(pUrm <= n && ! (A[pUrm] >= A[p] && LG[pUrm] == LG[p] - 1))
pUrm ++;
if(pUrm <= n)
p = pUrm;
else
p = -1;
}
while(p != -1);
Altă soluție \(O(n^2)\)
Putem regândi algoritmul de mai sus, astfel încât LG[i] să reprezinte lungime a maximă a unui subșir maximal care se termină în A[i].
- evident,
LG[1]=1; - pentru fiecare element
A[i]din șirul dat, vom parcurge elementele din fața sa și îl vom alege peA[p]atfel încâtA[p]≤A[i]șiLG[p]este maxim. În acest caz,A[i]se adaugă la subșirul care se încheie înA[p], adicăLG[i]devineLG[p]+1.
Lungimea subșriului maximal este cea mai mare valoare din LG, iar recosntituirea lui se face asemănător cu metoda de mai sus, folosind un șir de predecesori Prev[], unde Prev[i] este elementul din fața lui A[i] în subșirul crescător maximal care se încheie în A[i].
O soluție \(O(n \cdot \log n)\)
Algoritmul de mai sus are complexitate pătratică. Următoarea idee permite obținerea unui algoritm \(O(n \cdot \log{n})\).
Vom construi șirul D[], unde D[j] reprezintă un element al șirului A în care se termină un subșir crescător maximal de lungime j. Numărul de elemente pe care le va avea la final tabloul D va reprezenta lungimea subșirului crescător maximal al întregului șir A.
Vom construi șirul D în felul următor:
- fie
klungimea șiruluiD. Inițializămk=1șiD[k]=A[1]; - parcurgem șirul
A, începând de la al doilea element:- dacă
A[i]≥D[k], îl adăugăm peA[i]în șirulD– subșirul crescător maximal al luiAcrește cu încă un element - dacă
A[i]<D[k], vom înlocui cuA[i]pe cel mai mai mic element dinDcare este mai mare decât acesta
- dacă
ATENȚIE: Șirul D[] nu conține un subșir crescător al șirului A[]!
Exemplu
Pentru A=(5, 10, 7, 4, 5, 8, 9, 8, 10, 2).
Inițial k=1; D[k]=5; parcurgem șirul A, începând de la al doilea element:
i |
A[i] |
Condiție | Acțiune | D[] |
| 1 | 5 | - | - | (5) |
| 2 | 10 | A[i]>=D[k] |
adăugare | (5, 10) |
| 3 | 7 | A[i]<D[k] |
înlocuire | (5, 7) |
| 4 | 4 | A[i]<D[k] |
înlocuire | (4, 7) |
| 5 | 5 | A[i]<D[k] |
înlocuire | (4, 5) |
| 6 | 8 | A[i]>=D[k] |
adăugare | (4, 5, 8) |
| 7 | 9 | A[i]>=D[k] |
adăugare | (4, 5, 8, 9) |
| 8 | 8 | A[i]<D[k] |
înlocuire | (4, 5, 8, 8) |
| 9 | 10 | A[i]>=D[k] |
adăugare | (4, 5, 8, 8, 10) |
| 10 | 2 | A[i]<D[k] |
înlocuire | (2, 5, 8, 8, 10) |
Observații
- valorile din șirul
Dsunt în ordine crescătoare - fiecare element din șirul
Amodifică exact un element din șirulD(prin adăugare sau înlocuire).
Aceste observații ne permit să folosim căutarea binară pentru a stabili elementul din D care va fi înlocuit la fiecare pas: vom căuta primul element din D care este mai mare decât A[i]. Acest lucru poate fi realizat manual sau folosind funcția STL upper_bound. Complexitatea va fi \(O(n \cdot \log k)\).
Secvență C++
k = 1, D[k] = A[1];
for(int i = 2 ; i <= n ; i ++)
{
if(A[i] >= D[k])
P[++k] = A[i];
else
{
int st = 1 , dr = k , poz = k + 1;
while(st <= dr)
{
int m = (st + dr) / 2;
if(D[m] > A[i])
poz = m , dr = m - 1;
else
st = m + 1;
}
D[poz] = A[i];
}
}
cout << k << endl;
Reconstituirea subșirului
Pentru a reconstitui sub șirul crescător maximal vom folosi încă un șir P[], unde P[i] reprezintă poziția în șirul D unde a fost plasat (prin adăugare sau prin înlocuire) A[i]. Acesta este construit, pas cu pas, odată cu șirul D[]. Dacă un element A[i] face parte din subșirul crescător maximal, atunci P[i] reprezintă poziția sa în subșir.
Pentru exemplul de mai sus, șirul P[] va fi la final (1,2,2,1,2,3,4,4,5,1).
Reconstituirea propriu-zisă a subșirului se face în felul următor:
- fie
k– lungimea subșirului crescător maximal; - căutăm în șirul
P[]un element egal cuk. FieIkpoziția sa. AtunciA[Ik]reprezintă ultimul element al subșirului crescător maximal – cel de pe pozițiak; - căutăm în șirul
P[]un element egal cuk-1, anterior elementului de indiceIk. FieIk-1poziția sa. - analog se caută în
P[]valorilek-2, k-3, ..., 2, 1. - subșirul crescător maximal va fi
(A[I1], A[I2], ..., A[Ik]).
Secvența C++
În secvența de mai jos șirul I[] construit va conține indicii elementelor din A[] care fac parte din subșirul comun maximal.
k = 1;
D[k] = A[1];
P[1] = 1;
for(int i = 2 ; i <= n ; i ++)
if(A[i] >= D[k])
D[++k] = A[i], P[i] = k;
else
{
int st = 1 , dr = k , p = k + 1;
while(st <= dr)
{
int m = (st + dr) / 2;
if(D[m] > A[i])
p = m, dr = m - 1;
else
st = m + 1;
}
D[p] = A[i];
P[i] = p;
}
int j = n;
for(int i = k ; i >= 1 ; i --)
{
while(P[j] != i)
j --;
I[i] = j;
}
Probleme propuse
Numărul de drumuri în matrice
Introducere
Considerăm o matrice (labirint, teren, etc.) cu n linii și m coloane și un mobil aflat inițial în elementul de coordonate (1,1) – colțul stânga-sus, care se poate deplasa din elementul curent, de coordonate (i,j) în unul dintre elementele de coordonate (i+1,j) – aflat pe linia următoare, și (i,j+1) – aflat pe următoarea coloană. Să se determine în câte moduri poate ajunge mobilul în elementul de coordonate (n,m) – colțul dreapta-jos.
Problema are cel puțin două soluții, una care folosește metoda programării dinamice și una care se bazează pe combinatorică.
Rezolvare cu programare dinamică
Să constatăm mai întâi că numărul de drumuri căutat depinde de n și m – la mintea cocoșului, am putea spune. În general, numărul de drumuri de la poziția (1,1) la poziția (i,j) depinde de i și j, și numai de acestea. Atunci, formula recursivă care calculează rezultatul pentru (i,j) va depinde numai de i și de j!
Ne propunem să determinăm numărul de modalități în care mobilul ajunge de la poziția (1,1) în poziția (i,j). Fie acest număr \(F_{i,j}\). Constăm următoarele:
- în orice element de pe linia
1se poate ajunge într-un singur mod, dinspre stânga, deoarece în poziția(1,j)se poate ajunge numai din poziția(1,j-1). Astfel, \(F_{1,j} = 1\). - în orice element de pe coloana
1se poate ajunge într-un singur mod, dinspre linia anterioară, deoarece în poziția(i,1)se poate ajunge numai din poziția(i-1,1). Astfel, \(F_{i,1} = 1\). - în poziția
(i,j)(cui>1șij>1) se poate ajunge în două moduri:- de sus, din poziția
(i-1,j); - din stânga, din poziția
(i,j-1);
- de sus, din poziția
- atunci numărul de posibilități de a ajunge în poziția
(i,j)este numărul de posibilități de a ajunge în poziția(i-1,j)adunat cu numărul de posibilități de a ajunge în poziția(i,j-1). Astfel, \(F_{i,j} = F_{i-1,j} + F_{i,j-1}\). - rezultatul este \(F_{n,m}\).
În concluzie:
\( F_{i,j} = \begin{cases}
1& \text{dacă } i = 1 \text{ sau } j = 1, \\
F_{i-1,j} + F_{i,j-1}& \text{ dacă } i > 1 \text{ și } j > 1
\end{cases} \)
Deoarece formulele se suprapun, implementarea recursivă este foarte lentă. În consecință vom folosi o structură de date suplimentară, mai precis un tablou bidimensional în care A[i][j] reprezintă numărul de modalități de a ajunge din poziția (1,1) în poziția (i,j).
Acest tablou poate fi construit în maniera bottom-up:
int n, m, A[NN][NN]; ... for(int i = 1 ; i <= n ; ++ i) A[i][1] = 1; for(int j = 1 ; j <= m ; ++ j) A[1][j] = 1; for(int i = 2 ; i <= n ; ++ i) for(int j = 2 ; j <= m ; ++ j) A[i][j] = (A[i-1][j] + A[i][j-1]) % 9901; cout << A[n][m];
De asemenea, recurența poate fi rezolvată în maniera top-down, cu memoizare:
int n, m, A[NN][NN];
int F(int i , int j)
{
if(A[i][j] != 0)
return A[i][j];
if(i == 1 || j == 1)
A[i][j] = 1;
else
A[i][j] = (F(i-1,j) + F(i,j-1)) % 9901;
return A[i][j];
}
...
cout << F(n,m);
Rezolvare folosind calcul combinatorial
Pentru această soluție, să observăm că oricare traseu din poziția (1,1) în poziția (n,m), are respectă regulile de deplasare, va face exact n-1 pași spre dreapta și exact m-1 pași în jos. Traseele diferă numai prin ordinea acestor pași, nu prin numărul lor!
Atunci numărul de trasee este egal cu numărul de combinații de n-1 pași spre stânga și m-1 pași spre în jos; altfel spus n+m-2 pași, dintre care n-1 sunt în jos, adică: \(C_{n+m-2}^{n-1}\).
Observații
- numărul de trasee crește foarte repede. Pentru valori relativ mici ale lui
nșimse produce overflow. Pentru valori mai mari ale acestora este necesară implementarea operațiilor cu numere mari! - de multe ori, pentru a rezolva problema cu valori mai mari ale lui
nșim, fără însă a implementa operații cu numere mari, se cere determinarea restului împărțirii rezultatului la o valoare datăMOD, adică realizarea operațiilor moduloMOD! - rezolvarea cu programare dinamică are complexitatea timp \(O(n \cdot m)\). Spațiul de memorie poate fi optimizat, folosind doar două tablouri unidimensionale, unul pentru linia curentă și celălalt pentru linia precedentă. Asta deoarece în calculul valorilor de pe linia curentă
ise folosesc doar elemente de pe aceasta și de pe linia precedentă,i-1. - complexitatea rezolvării cu combinări este cea a algoritmului de determinare a combinărilor. Acestea pot fi determinate fie folosind formula uzuală, fie folosind triunghiul lui Pascal.
Probleme propuse
Matrice Fibonacci
Introducere
Șirul lui Fibonacci este definit astfel:
$$ F_n = \begin{cases}
1& \text{dacă } n = 1 \text{ sau } n = 2 ,\\
F_{n-1} + F_{n-2} & \text{dacă } n > 2.
\end{cases} $$
Pentru a determina al n-termen a șirului putem folosi diverse metode. Acest articol prezintă un algoritm de complexitate \(O(n)\) care determină al n-lea termen.
Prezentul articol prezintă un algoritm de complexitate logaritmică, bazat pe înmulțirea rapidă a matricelor.
Matrice Fibonacci
Considerăm următoarea matrice: \( Q = \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right) \). Dacă extindem șirul lui Fibonacii cu încă un element, \( F_0 = 0 \), observăm că: \( Q = \left( \begin{matrix} F_2& F_1\\ F_1& F_0\end{matrix} \right) \). Să calculăm \(Q^2\) și \(Q^3\):
$$ \begin{align} Q^2 & = Q \times Q \\
& = \left( \begin{matrix} F_2& F_1\\ F_1& F_0\end{matrix} \right) \times \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right)\\
& = \left( \begin{matrix}
F_2 \cdot 1 + F_1 \cdot 1& F_2 \cdot 1 + F_1 \cdot 0 \\
F_1 \cdot 1 + F_0 \cdot 1& F_1 \cdot 1 + F_0 \cdot 0
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_2 + F_1 & F_2 \\
F_1 + F_0 & F_1
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_3 & F_2 \\
F_2 & F_1
\end{matrix} \right) \\
\end{align}
$$
Similar:
$$ \begin{align} Q^3 & = Q^2 \times Q \\
& = \left( \begin{matrix} F_3 & F_2\\ F_2 & F_1\end{matrix} \right) \times \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right)\\
& = \left( \begin{matrix}
F_3 \cdot 1 + F_2 \cdot 1& F_3 \cdot 1 + F_2 \cdot 0 \\
F_2 \cdot 1 + F_1 \cdot 1& F_2 \cdot 1 + F_1 \cdot 0
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_3 + F_2 & F_3 \\
F_2 + F_1 & F_2
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_4 & F_3 \\
F_3 & F_2
\end{matrix} \right) \\
\end{align}
$$
Observăm că \( Q^n = \left( \begin{matrix} F_{n+1}& F_n\\ F_n& F_{n-1}\end{matrix} \right) \), lucru ușor de demonstrat prin inducție matematică.
Concluzie: Dacă \( Q = \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right) \), atunci \( Q^n = \left( \begin{matrix} F_{n+1}& F_n\\ F_n& F_{n-1}\end{matrix} \right) \).
Algoritm
Pentru a determina \(F_n\), considerăm matricea \( Q = \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right) \), pe care o ridicăm la puterea n. Pentru a efectua repede calculele, folosim exponențierea rapidă.
Problema #Fibonacci2 cere determinarea celui de-al n-lea termen al șirului lui Fibonacii, modulo 666013. Succes!
Bibliografie
Algoritmul lui Kruskal
Considerăm un graf neorientat ponderat (cu costuri) conex G. Se numește arbore parțial un graf parțial al lui G care este arbore. Se numește arbore parțial de cost minim un arbore parțial pentru care suma costurilor muchiilor este minimă.
Dacă graful nu este conex, vorbim despre o pădure parțială de cost minim.
Algoritmul lui Kruskal permite determinarea unui arbore parțial de cost minim (APM) într-un graf ponderat cu N noduri.
Descrierea algoritmului
Pentru a determina APM-ul se pleacă de la o pădure formată din N subarbori. Fiecare nod al grafului reprezintă inițial un subarbore. Aceștia vor fi reuniți succesiv prin muchii, până când se obține un singur arbore (dacă graful este conex) sau până când acest lucru nu mai este posibil (dacă graful nu este conex).
Algoritmul este:
- se ordonează muchiile grafului crescător după cost;
- se analizează pe rând muchiile grafului, în ordinea crescătoare a costurilor;
- pentru fiecare muchie analizată:
- dacă extremitățile muchiei fac parte din același subarbore, muchia se ignoră
- dacă extremitățile muchiei fac parte din subarbori diferiți, aceștia se vor reuni, iar muchia respectivă face parte din APM.
Principala dificultate în algoritmul descris mai sus este stabilirea faptului că extremitățile muchiei curente fac sau nu parte din același subarbore. În acest scop vom stabili pentru fiecare subarbore un nod special, numit reprezentant al (sub)arborelui și pentru fiecare nod din graf vom memora reprezentantul său (de fapt al subarborelui din care face parte) într-un tablou unidimensional.
Pentru a stabili dacă două noduri fac sau nu parte din același subarbore vom verifica dacă ele au același reprezentant. Pentru a reuni doi subarbori vom înlocui pentru toate nodurile din subarborele B cu reprezentantul subarborelui A.
Înlocuirile descrise mai sus sunt simple dar lente. Pentru o implementare mai eficientă a algoritmului se poate folosi conceptul de Padure de mulțimi disjuncte, descris în acest articol.
Exemplu
Vom determina, folosind Algoritmul lui Kruskal, arborele parțial de cost minim pentru graful de mai jos.
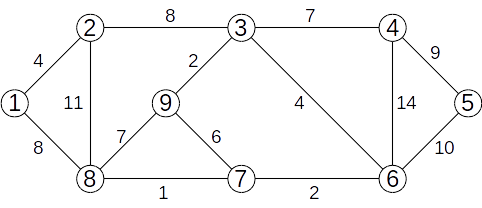
Muchiile se vor analiza în ordinea crescătoare a costului.
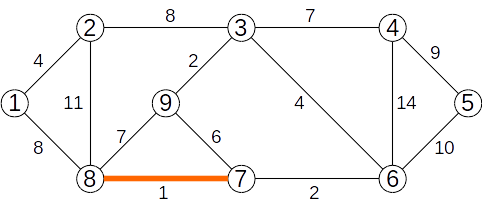
Se adaugă muchia (7,8) de cost 1
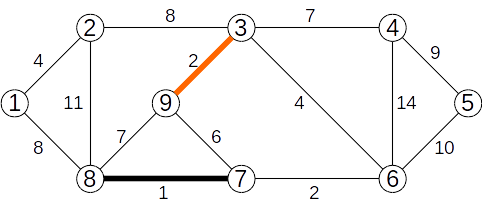
Se adaugă muchia (3,9) de cost 2
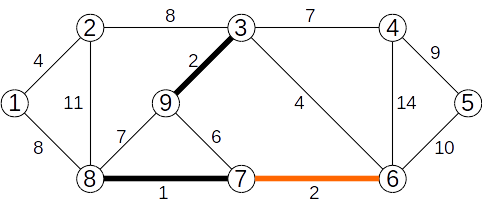
Se adaugă muchia (6,7) de cost 2
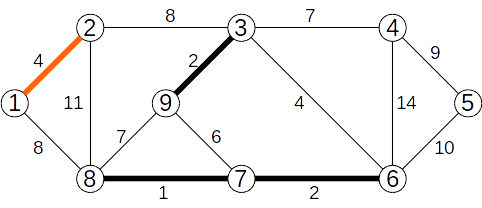
Se adaugă muchia (1,2) de cost 4
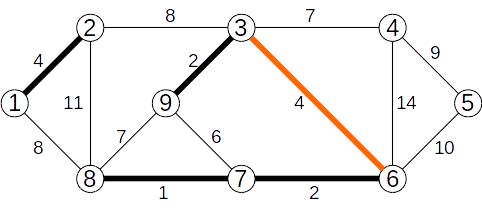
Se adaugă muchia (3,6) de cost 1
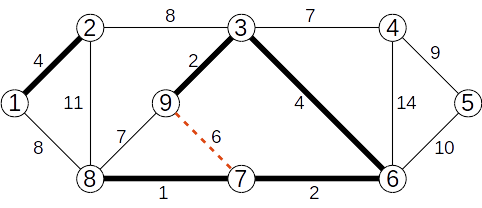
Se ignoră muchia (7,9) de cost 6
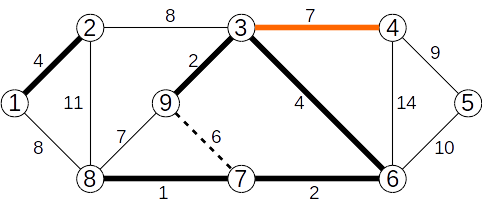
Se adaugă muchia (3,4) de cost 7
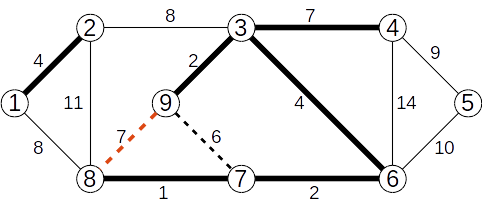
Se ignoră muchia (8,9) de cost 7
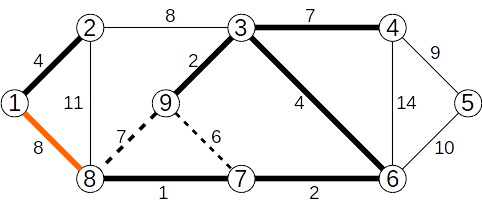
Se adaugă muchia (1,8) de cost 8
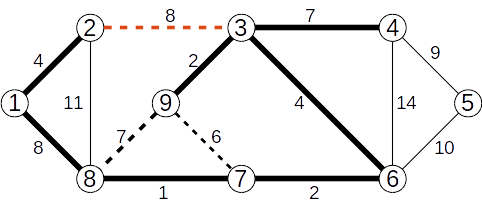
Se ignoră muchia (2,3) de cost 8
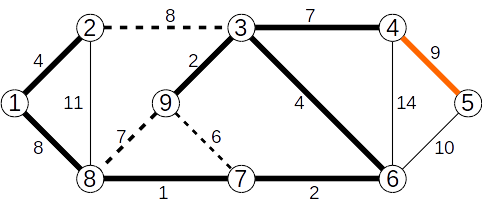
Se adaugă muchia (4,5) de cost 9
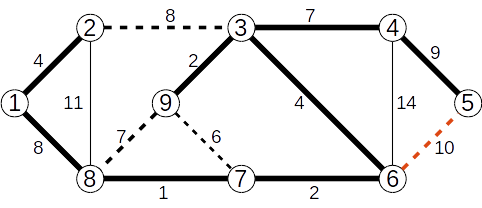
Se ignoră muchia (5,6) de cost 10
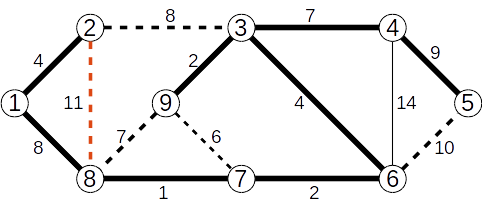
Se ignoră muchia (2,8) de cost 11
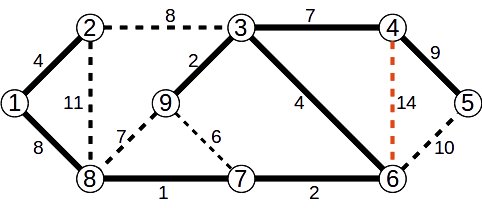
Se ignoră muchia (4,6) de cost 14
Vom determina, folosind Algoritmul lui Kruskal, arborele parțial de cost minim pentru graful de mai jos:
Muchiile se vor analiza în ordinea următoare:
| 1. | |
Se adaugă muchia (7,8) de cost 1 |
| 2. | |
Se adaugă muchia (3,9) de cost 2 |
| 3. | |
Se adaugă muchia (6,7) de cost 2 |
| 4. | |
Se adaugă muchia (1,2) de cost 4 |
| 5. | |
Se adaugă muchia (3,6) de cost 1 |
| 6. | |
Se ignoră muchia (7,9) de cost 6 |
| 7. | |
Se adaugă muchia (3,4) de cost 7 |
| 8. | |
Se ignoră muchia (8,9) de cost 7 |
| 9. | |
Se adaugă muchia (1,8) de cost 8 |
| 10. | |
Se ignoră muchia (2,3) de cost 8 |
| 11. | |
Se adaugă muchia (4,5) de cost 9 |
| 12. | |
Se ignoră muchia (5,6) de cost 10 |
| 13. | |
Se ignoră muchia (2,8) de cost 11 |
| 14. | |
Se ignoră muchia (4,6) de cost 14 |
Secvență C++
Următoarea secvență determină costul total al APM-ului, folosind algoritmul lui Kruskal. Presupunem că graful are cel mult 100 de noduri.
struct muchie{
int i,j,cost;
};
int n , m , t[101];
muchie x[5000];
int main()
{
cin >> n >> m;
for(int i = 0 ; i < m ; ++i)
cin >> x[i].i >> x[i].j >> x[i].cost;
//sortare tablou x[] după campul cost
// ... de completat
//initializare reprezentanti
for(int i =1 ; i <= n ; ++i)
t[i] = i;
//determinare APM
int S = 0;
for(int i = 0 ; i < m ; i ++)
if(t[x[i].i] != t[x[i].j]) // extremitatile fac parte din subrabori diferiti
{
S += x[i].cost;
//reunim subarborii
int ai = t[x[i].i], aj = t[x[i].j];
for(int j =1 ; j <= n ; ++j)
if(t[j] == aj)
t[j] = ai;
}
cout << S << "\n";
return 0;
}
Vezi și
Programare dinamică - introducere
Programarea dinamică este o metodă de rezolvare a unor probleme de informatică în care se cere de regulă determinarea unei valori maxime sau minime, sau numărarea elementelor unei mulțimi.
Similar cu metoda Divide et Impera, problema se împarte în subprobleme:
- de aceeași natură cu problema inițială;
- de dimensiuni mai mici;
- spre deosebire de Divide et Impera, problemele nu mai sunt independente, ci se suprapun – probleme superpozabile!
- rezolvarea optimă a problemei inițiale depinde de rezolvarea optimă a subproblemelor – principiul optimalității!
Observație: Subproblemele se mai numesc și stări ale problemei.
 Problemă: Se dă o scară cu
Problemă: Se dă o scară cu N trepte. Un individ se află în partea de jos a scării și poate să urce câte o treaptă la un pas, sau câte două trepte la un pas. În câte moduri poate urca scara?
Exemplu: Observăm că dacă scara are o treaptă, ea poate fi urcată într-un singur mod, iar dacă are două trepte, sunt două modalități de a urca scara: doi pași de o treaptă sau un un pas de două trepte. Pentru N=4, scara poate fi urcată în 5 moduri:
1 1 1 11 1 21 2 12 1 12 2
Rezolvare: Este o problemă de numărare; dacă numerotăm treptele, observăm că pe treapta N se poate ajunge de pe treapta N-1 (cu un pas de o treaptă) sau de pe treapta N-2 (cu un pas de două trepte), cazurile N=1 și N=2 fiind particulare. Atunci, numărul de variate de a urca N trepte este egal cu numărul de variante de a urca N-1 trepte, plus numărul de variante de a urca N-2 trepte. Deducem deci următoarea relație de recurență, în care \( T(n) \) reprezintă numărul de modalități de a urca o scară cu n trepte:
$$ T(n) = \begin{cases}1, & n = 1\\ 2, & n = 2\\ T(n-1)+T(n-2), & n > 2 \end{cases} $$
Constatăm că formula anterioară respectă proprietățile descrise mai sus pentru probleme rezolvabile prin programare dinamică: subprobleme de același tip, de dimensiuni mai mici și care se suprapun; în determinarea lui \(T(n)\) intervine \(T(n-1)\) și \(T(n-2)\). În determinarea lui \(T(n-1)\) apare din nou \(T(n-2)\), ș.a.m.d., situație care face ca utilizarea recursivității să fie foarte ineficientă.
De fapt, putem observa că formula de mai sus este de fapt definiția șirului lui Fibonacci, despre care am văzut deja că are o soluție de complexitate \(O(n) \), construind termenii în ordine crescătoare, folosind eventual un tablou unidimensional (sau doar trei variabile simple).
Determinarea relației de recurență este o caracteristică a programării dinamice, și una dintre dificultățile principale în rezolvarea problemei. Capacitatea de a identica relațiile de recurență – și deci de a rezolva problema – se dezvoltă treptat, prin rezolvarea de probleme.
Odată identificată relația de recurență, este necesară stabilirea unui algoritm de rezolvare a recurenței. Datorită suprapunerii subproblemelor, utilizarea recursivității este foarte neeficientă. De regulă se folosește o structură de date suplimentară – tablou unidimensional, bidimensional sau cu mai multe dimensiuni (în funcție de numărul variabilelor care intervin în relația de recurență).
Soluția problemei se află într-un element al tabloului sau se poate determina folosind o parte a elementelor acestuia. Elementele tabloului se vor determina unul câte unul, până când sunt determinate toate elementele necesare pentru aflarea soluției!
Pentru problema scării, notăm tabloul necesar cu V[]. Este un tablou unidimensional deoarece în relația de recurență apare o singură variabilă (n); formula recursivă devine:
V[1] = 1,V[2]=2;V[n] = V[n-1] + V[n-2], pentrun>2;
Inițializăm primele două elemente ale tabloului, iar celelalte elemente vor fi construite unul după altul, de la stânga spre dreapta. Rezultatul se va găsi în V[n].
V[1] = 1, V[2] = 2;
for(int i = 3 ; i <= n ; i ++)
V[i] = V[i-1] + V[i-2];
cout << V[n];
Metoda folosită mai sus pentru rezolvarea recurenței se numește bottom-up. Tabloul se construiește “de jos în sus”, element cu element, până la cel căutat. Toate elementele tabloului au fost completate cu valori.
O altă metodă de rezolvare a recurenței este top-down, “de sus în jos”. Metoda folosește recursivitatea, dar, pentru a evita rezolvarea de mai multe ori a subproblemelor, folosește memoizarea: soluția fiecărei subprobleme rezolvate este memorată într-un tablou și când trebuie să rezolvăm aceeași subproblemă cunoaștem deja soluția!
Următoarea secvență rezolvă problema scării (șirul lui Fibonacci) folosind memoizarea:
long long V[100];
long long T(int n)
{
if(V[n] != 0)
return V[n];
if(n < 3)
V[n] = n;
else
V[n] = T(n-1) + T(n-2);
return V[n];
}
Concluzii
- o problemă se rezolvă prin metoda programării dinamice dacă se poate descompune în subprobleme superpozabile și care respectă principiul optimalității;
- se identifică relația de recurență pentru subprobleme și structura de date ajutătoare;
- se rezolvă recurența, folosind metoda bottom-up sau top-down.
Metoda Greedy
Metoda Greedy este o metodă care poate fi uneori folosită în rezolvarea problemelor de următorul tip:
Se dă o mulțime
A. Să se determine o submulțimeBa luiAastfel încât să fie îndeplinite anumite condiții – acestea depinzând de problema propriu-zisă.
Algoritm general
De regulă problema dată poate fi rezolvată prin mai multe metode, printre care și Greedy. O rezolvare generală de tip Greedy a problemei de mai sus este următoarea:
B ← ∅
terminat ← FALSE
Execută
Alege convenabil x ∈ A
Dacă x poate fi adăugat în B Atunci
B ← B ∪ {x}
Altfel
terminat ← TRUE
SfârșitDacă
Cât timp terminat=FALSE
Altfel spus, pornim de la mulțimea vidă și adăugăm în mod repetat în B elemente până când acest lucru nu mai este posibil.
Observații
- stabilirea elementului care va fi adăugat în soluția
Bse face alegându-l pe cel mai bun din acel moment – este un optim local. Din acest motiv se numește Greedy (lacom); - după adăugarea în soluția
Ba unui anumit element, acesta va rămâne în soluție până la final. Nu există un mecanism de revenire la la un pas anterior, precum la metoda Backtracking; - alegerea optimului local nu duce întotdeauna la cea mai bună soluție
B; metoda Greedy nu este întotdeauna corectă; - schema prezentată mai sus este vagă și nu poate fi standardizată – să avem un algoritm detaliat care să poată fi aplicat de fiecare dată;
- sunt relativ puține probleme care pot fi rezolvate cu metoda Greedy;
- complexitatea metodei este de regulă polinomială – \( O(n^k)\), unde \(k\) este constant;
- folosim metoda Greedy în două situații:
- știm sigur că rezolvarea este corectă (avem o demonstrație de natură matematică a corectitudinii);
- nu avem decât soluții exponențiale (de tip Backtracking) și un algoritm Greedy dă o soluție nu neapărat optimă, dar acceptabilă.
- de regulă, înainte de începe alegerea elementelor convenabile din mulțimea
A, elementele sale sunt ordonate după un criteriu specific, astfel încât alegerea optimului local să fie cât mai rapidă;
Există câteva probleme celebre de algoritmică ce pot fi rezolvate cu metoda Greedy:
- Problema spectacolelor
- Problema continuă a rucsacului
- Algoritmul lui Dijkstra pentru determinarea drumurilor de cost minim într-un graf
- Algoritmul lui Prim și Algoritmul lui Kruskal pentru determinarea arborelui parțial de cost minim al unui graf
Greedy euristic
Există probleme pentru care avem nevoie de o rezolvare acceptabilă, chiar dacă singurele soluții demonstrate corecte sunt exponențiale, de multe ori inutile în practică.
Putem să aplicăm pentru aceste probleme metoda Greedy, obținând soluții neoptime, dar suficient de apropiate de soluția optimă pentru a fi acceptabile. Mai mult, în implementarea algoritmului se pot aplica diverse artificii la alegerea optimului local care pot duce la soluții din ce în ce mai bune, deși nu neapărat optime.
Un algoritm care obține o soluție acceptabilă, deși nu neapărat optimă, se numește Greedy euristic.
O problemă cu o soluție euristică interesantă este Săritura calului1 (enunț modificat):
Se consideră o tablă de șah cu n linii și m coloane. La o poziție dată se află un cal de șah, acesta putându-se deplasa pe tablă în modul specific acestei piese de șah (în L). Să se determine o modalitate de parcurgere a tablei de către cal, astfel încât acesta să nu treacă de două ori prin aceeași poziție.
Pentru dimensiuni mici ale tablei se poate folosi metoda Backtracking, aceasta determinând o soluție optimă. Dacă dimensiunile tablei sunt mari, metoda Backtracking nu mai poate fi folosită. Putem încerca o strategie Greedy:
- plecăm de la poziția inițială,
istart jstart - cât timp este posibil
- alegem o poziție vecină în L cu poziția curentă în care nu am mai fost
- marcăm poziția aleasă într-un anumit mod și o considerăm poziție curentă
Succesul algoritmului Greedy stă în alegerea poziției vecine! Desigur, nu orice metodă duce la parcurgerea completă a tablei. Neexistând un mecanism de întoarcere la o stare anterioară, când nu mai găsim poziție vecină liberă pentru poziția curentă algoritmul se încheie.
O strategie de succes este să alegem pentru poziția curentă poziția vecină cel mai greu accesibilă la pasul următor – poziția vecină cu număr minim de vecini neparcurși. Teoretic, fiecare poziție de pe tablă are 8 poziții vecini, dar unele sunt în afara tablei, altele sunt deja parcurse, astfel că putem alege dintre cei 8 vecini ai poziției curente un vecin care la rândul său are număr minim de vecini neparcurși.
Mai mult, dacă există mai mulți vecini ai poziției curente cu număr minim de vecini neparcurși, putem varia vecinul cu care vom continua: primul găsit, ultimul găsit, cel mai de sus, cel mai de jos, îl alegem aleatoriu, etc., sporind șansele de a realiza o parcurgere completă a tablei.
Metoda Backtracking
Metoda backtracking poate fi folosită în rezolvarea a diverse probleme. Este o metodă lentă, dar de multe ori este singura pe care o avem la dispoziție!
Introducere
Metoda backtracking poate fi aplicată în rezolvarea problemelor care respectă următoarele condiții:
- soluția poate fi reprezentată printr-un tablou
x[]=(x[1], x[2], ..., x[n]), fiecare elementx[i]aparținând unei mulțimi cunoscuteAi; - fiecare mulțime
Aieste finită, iar elementele ei se află într-o relație de ordine precizată – de multe ori celenmulțimi sunt identice; - se cer toate soluțiile problemei sau se cere o anumită soluție care nu poate fi determinată într-un alt mod (de regulă mai rapid).
Algoritmul de tip backtracking construiește vectorul x[] (numit vector soluție) astfel:
Fiecare pas k, începând (de regulă) de la pasul 1, se prelucrează elementul curent x[k] al vectorului soluție:
x[k]primește pe rând valori din mulțimea corespunzătoareAk;- la fiecare pas se verifică dacă configurația curentă a vectorului soluție poate duce la o soluție finală – dacă valoarea lui
x[k]este corectă în raport cux[1],x[2], …x[k-1]:- dacă valoarea nu este corectă, elementul curent
X[k]primește următoarea valoare dinAksau revenim la elementul anteriorx[k-1], dacăX[k]a primit toate valorile dinAk– pas înapoi; - dacă valoarea lui
x[k]este corectă (avem o soluție parțială), se verifică existența unei soluții finale a problemei:- dacă configurația curentă a vectorului soluție
xreprezintă soluție finală (de regulă) o afișăm; - dacă nu am identificat o soluție finală trecem la următorul element,
x[k+1], și reluăm procesul pentru acest element – pas înainte.
- dacă configurația curentă a vectorului soluție
- dacă valoarea nu este corectă, elementul curent
Pe măsură ce se construiește, vectorul soluție x[] reprezintă o soluție parțială a problemei. Când vectorul soluție este complet construit, avem o soluție finală a problemei.
Exemplu
Să rezolvăm următoarea problemă folosind metoda backtracking, “cu creionul pe hârtie”: Să se afișeze permutările mulțimii {1, 2, 3}.
Ne amintim că un șir de numere reprezintă o permutare a unei mulțimi M dacă și numai dacă conține fiecare element al mulțimii M o singură dată. Altfel spus, în cazul nostru:
- are exact
3elemente; - fiecare element este cuprins între
1și3; - elementele nu se repetă.
Pentru a rezolva problemă vom scrie pe rând valori din mulțimea dată și vom verifica la fiecare pas dacă valorile scrise duc la o permutare corectă:
k |
x[] |
Observații |
|---|---|---|
1 |
1 – – | corect, pas înainte |
2 |
1 1 – | greșit |
2 |
1 2 – | corect, pas înainte |
3 |
1 2 1 | greșit |
3 |
1 2 2 | greșit |
3 |
1 2 3 | soluție finală 1 |
3 |
1 2 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
1 3 – | corect, pas înainte |
3 |
1 3 1 | greșit |
3 |
1 3 2 | soluție finală 2 |
3 |
1 3 3 | greșit |
3 |
1 3 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
1 ! – | am terminat valorile posibile pentru x[ 2 ], pas înapoi |
1 |
2 – – | corect, pas înainte |
2 |
2 1 – | corect, pas înainte |
3 |
2 1 1 | greșit |
3 |
2 1 2 | greșit |
3 |
2 1 3 | soluție finală 3 |
3 |
2 1 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
2 2 – | greșit |
2 |
2 3 – | corect, pas înainte |
3 |
2 3 1 | soluție finală 4 |
3 |
2 3 2 | greșit |
3 |
2 3 3 | greșit |
3 |
2 3 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
2 ! – | am terminat valorile posibile pentru x[ 2 ], pas înapoi |
1 |
3 – – | corect, pas înainte |
2 |
3 1 – | corect, pas înainte |
3 |
3 1 1 | greșit |
3 |
3 1 2 | soluție finală 5 |
3 |
3 1 3 | greșit |
3 |
3 1 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
3 2 – | corect, pas înainte |
3 |
3 2 1 | soluție finală 6 |
3 |
3 2 2 | greșit |
3 |
3 2 3 | greșit |
3 |
3 2 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
3 3 – | greșit |
2 |
3 ! – | am terminat valorile posibile pentru x[ 2 ], pas înapoi |
1 |
! – – | am terminat valorile posibile pentru x[ 1 ], pas înapoi |
Formalizare
Pentru a putea realiza un algoritm backtracking pentru rezolvarea unei probleme trebuie să răspundem la următoarele întrebări:
- Ce memorăm în vectorul soluție
x[]? Uneori răspunsul este direct; de exemplu, la generarea permutărilor vectorul soluție reprezintă o permutare a mulțimiiA={1,2,...,n}. În alte situații, vectorul soluție este o reprezentare mai puțin directă a soluției; de exemplu, generarea submulțimilor unei mulțimi folosind vectori caracteristici sau Problema reginelor. - Ce valori poate lua fiecare element
x[k]vectorului soluție și câte elemente poate aveax[]? Altfel spus, care sunt mulțimileAk. Vom numi aceste restricții condiții externe. Cu cât condițiile externe sunt mai restrictive (cu cât mulțimileAkau mai puține elemente), cu atât va fi mai rapid algoritmul! - Ce condiții trebuie să îndeplinească
x[k]ca să fie considerat corect? Elementulx[k]a primit o anumită valoare, în conformitate ce condițiile externe. Este ea corectă? Poate conduce la o soluție finală? Aceste condiții se numesc condiții interne și în ele pot să intervină doarx[k]și elementelex[1],x[2], …,x[k-1]. Elementelex[k+1], …,x[n]nu poti apărea în condițiile interne deoarece încă nu au fost generate!!! - Am găsit o soluție finală? Elementul
x[k]a primit o valoare conformă cu condițiile externe, care respectă condițiile interne. Am ajuns la soluție finală sau continuăm cux[k+1]?
Exemplu. Pentru problema generării permutărilor mulțimii \(A=\{1, 2, 3, …, n\}\), condițiile de mai sus sunt:
- Vectorul soluție conține o permutare a mulțimii \( A \);
- Condiții externe: \( x[k] \in \{1,2,3,…,n\} \) sau \( x[k] = \overline{1,n} \), pentru \( k = \overline{1,n} \)
- Condiții interne: \( x[k]\neq x[i] \), pentru \( i = \overline{1,k-1} \)
- Condiții de existență a soluției: \( k = n \)
Algoritmul general
Metoda backtracking poate fi implementată iterativ sau recursiv. În ambele situații se se folosește o structură de deate de tip stivă. În cazul implementării iterative, stiva trebuie gestionată intern în algoritm – ceea ce poate duce la dificulăți în implementăre. În cazul implementării recursive se folosește spațiu de memorie de tip stivă – STACK alocat programului; implementarea recursivă este de regulă mai scurtă și mai ușor de înțeles. Acest articol prezintă implementări recursive ale metodei.
Următorul subprogram recursiv prezintă algoritmul la modul general:
- la fiecare apel
BACK(k)se generează valori pentru elementulx[k]al vectorului soluție; - instrucțiunea
Pentrumodelează condițiile externe; - subprogramul
OK(k)verifică condițiile interne - subprogramul
Solutie(k)verifică dacă configurația curentă a vectorului soluție reprezintă o soluție finală - subprogramul
Afisare(k)tratează soluția curentă a problemei – de exemplu o afișează!
subprogram BACK(k)
┌ pentru fiecare element i din A[k] executa
│ x[k] ← i
│ ┌ daca OK(k) atunci
│ │ ┌ daca Solutie(k) atunci
│ │ │ Afisare(k)
│ │ │ altfel
│ │ │ BACK(k+1)
│ │ └■
│ └■
└■
sfarsit_subprogram
Observații:
- de cele mai multe ori mulțimile \(A\) sunt de forma \( A=\{1, 2, 3, …. , n \} \) sau \( A=\{1, 2, 3, …. , m \} \) sau \( A=\{a, a + 1, a + 2, …. , b \} \) sau o altă formă astfel încât să putem scrie instrucțiunea
Pentruconform specificului limbajului de programare folosit – eventual folosind o structură repetitivă de alt tip! Dacă este necesar, trebuie realizate unele transformări încât mulțimile să ajungă la această formă! - elementele mulțimii \( A \) pot fi in orice ordine. Contează însă ordinea în care le vom parcurge în instrucțiunea
Pentru, deoarece în probleme este precizată de obicei o anumită ordine în care trebuie generate soluțiile:- dacă parcurgem elementele lui \( A \) în ordine crescătoare vom obține soluții în ordine lexicografică;
- dacă parcurgem elementele lui \( A \) în ordine descrescătoare vom obține soluții în ordine invers lexicografică.
- în anumite probleme determinarea unei soluții finale nu conduce la întreruperea apelurilor recursive. Un exemplu este generarea submulțimilor unei mulțimi. În acest caz algoritmul de mai sus poate fi modificat astfel:
┌ daca OK(k) atunci
│ ┌ daca Solutie(k) atunci
│ │ Afisare(k)
│ └■
│ BACK(k+1)
└■
Bineînțeles, trebuie să ne asigurăm că apelurile recursive se opresc!
Un șablon C++
Următoarea secvență C++ oferă un șablon pentru rezolvarea unei probleme oarecare folosind metoda backtracking. Vom considera în continuare următoarele condiții externe: \( x[k] = \overline{A,B} \), pentru \( k = \overline{1,n} \). În practică \( A \) și \( B \) vor avea valori specifice problemei:
#include <fstream>
using namespace std;
int x[10] ,n;
int Solutie(int k){
// x[k] verifică condițiile interne
// verificare dacă x[] reprezintă o soluție finală
return 1; // sau 0
}
int OK(int k){
// verificare conditii interne
return 1; // sau 0
}
void Afisare(int k)
{
// afișare/prelucrare soluția finală curentă
}
void Back(int k){
for(int i = A ; i <= B ; ++i)
{
x[k]=i;
if( OK(k) )
if(Solutie(k))
Afisare(k);
else
Back(k+1);
}
}
int main(){
//citire date de intrare
Back(1);
return 0;
}
De multe ori condițiile de existență a soluției sunt simple și nu se justifică scrierea unei funcții pentru verificarea lor, ele putând fi verificate direct în funcția Back().
De cele mai multe ori, rezolvarea unei probleme folosind metoda backtracking constă în următoarele:
- stabilirea semnificației vectorului soluție;
- stabilirea condițiilor externe;
- stabilirea condițiilor interne;
- stabilirea condițiilor de existența a soluției finale;
- completarea adecvată a șablonului de mai sus!
Complexitatea algoritmului
Algoritmii Backtracking sunt exponențiali. Complexitatea depinde de la problemă la problemă dar este de tipul \( O(a^n) \). De exemplu:
- generarea permutărilor unei mulțimi cu
nelemente are complexitatea \( O(n!)\); - generarea submulțimilor unei mulțimi cu
nelemente are complexitatea \( O(2^n) \) - produsul cartezian \( A^n\) unde mulțimea \( A=\{1,2,3,…,m\}\) are complexitatea \(O(m^n)\)
- etc.
PbInfo propune spre rezolvare cu metoda backtracking câteva zeci de probleme! SUCCES!
Citește mai departe
Generarea permutărilor
Citiți mai întâi Metoda backtraking
Prin permutare a unei mulțimi înțelegem o aranjare a elementelor sale, într-o anumită ordine. Este cunoscut, printre altele, faptul că numărul de permutări ale unei mulțimi cu n elemente este \(P_n = n! = 1 \cdot 2 \cdot \cdot \cdots \cdot n \). Prin convenție, \(P_0 = 0! = 1\).
Problema
Fie un număr natural
n. Să se afișeze, în ordine lexicografică, permutările mulțimii \( \left\{ 1, 2, , \cdots , n \right\}\).
Exemplu
Pentru n=3, se va afișa:
1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3 2 1
Rezolvare
Bineînțeles, vom rezolva problema prin metoda backtracking. Vectorul soluție x[] va reprezenta o permutare candidat. Să ne gândim care sunt proprietățile unei permutări, pe care le va respecta și vectorul x[]:
- elementele sunt numere naturale cuprinse între
1șin; - elementele nu se repetă;
- vectorul
x[]se construiește pas cu pas, element cu element. El va conține o permutare validă când va conținenelemente, desigur corecte.
Cele observate mai sus ne permit să precizăm condițiile specifice algoritmului backtracking, într-un mod mai formal:
- condiții externe: \( x[k] \in \left\{ 1,2, \cdots, n \right\} \);
- condiții interne: \(x[k] \notin \left\{ x[ 1 ],x[ 2 ], \cdots, x[ k-1 ] \right\}\), pentru \( k \in \left\{2,3, \cdots, n \right \} \)
- condiții de existență a soluției: \(k = n\)
Sursă C++
Următorul program afișează pe ecran permutările, folosind un algoritm recursiv:
#include <iostream>
using namespace std;
int x[10] ,n;
void Afis()
{
for( int j=1;j<=n;j++)
cout<<x[j]<<" ";
cout<<endl;
}
bool OK(int k){
for(int i=1;i<k;++i)
if(x[k]==x[i])
return false;
return true;
}
bool Solutie(int k)
{
return k == n;
}
void back(int k){
for(int i=1 ; i<=n ; ++i)
{
x[k]=i;
if( OK(k) )
if(Solutie(k))
Afis();
else
back(k+1);
}
}
int main(){
cin>>n;
back(1);
return 0;
}
Semnificația funcțiilor
void Afis();afișează soluția curentă. Când se apelează, vectorul soluțiexarenelemente, reprezentând o permutare completă;bool OK(int k);verifică condițiile interne. La apel,x[k]tocmai a primit o valoare conform condițiilor externe. Prin funcțiaOK()se va verifica dacă această valoare este validă;bool Solutie(int k);verifică dacă avem o soluție completă. Acest lucru se întâmplă când permutarea este completă – am dat o valoare corectă ultimului element al tabloului,x[n], adică atunci cândk=n;void back(int k);– apelul acestei funcții dă valori posibile elementuluix[x]al vectorului soluție și le verifică:- se parcurg valorile pe care le pot lua elementele vectorului, conform condițiilor externe (în acest caz,
1..n);- se memorează în
x[k]valoarea curentă; - dacă valoarea lui
x[k]este corectă, conform condițiilor interne, se verifică dacă avem o soluție completă. În caz afirmativ se afișează această soluție, în caz contrar se trece la următorul element, prin apelul recursiv;
- se memorează în
- la finalul parcurgerii, se revine la elementul anterior al vectorului
x, prin revenirea din apelul recursiv.
- se parcurg valorile pe care le pot lua elementele vectorului, conform condițiilor externe (în acest caz,
Observații
- generarea valorilor din vectorul soluție începe cu primul element al acestuia,
x[ 1 ]; în consecință, apelul principal al funcțieiback()esteback(1); - generarea permutărilor în ordine lexicografică se obține datorită faptului că, în funcția
back()valorile posibile pe care le primeștex[k]sunt parcurse în ordine crescătoare (for(int i=1 ; i<=n ; ++i)....). Dacă am fi parcurs valorile de lanla1, s-ar fi generat permutările în ordine invers lexicografică; - algoritmul este exponențial și poate fi folosit numai pentru valori mici ale lui
n. O soluție ceva mai bună se poate obține dacă, pentru a stabili corectitudinea condițiilor interne, evităm parcurgerea elementelor deja memorate în vectorul soluție. Acest lucru poate fi realizat prin intermediul unui vector caracteristic, cu semnificația:v[p] = 1dacă valoareapface deja parte din permutare, șiv[p]=0dacăpnu face parte din permutare.
Varianta iterativă
În general, algoritmii nerecursivi sunt mai buni decât cei recursivi, deși uneori sunt mai dificil de urmărit. Următorul program iterativ afișează și el permutările pe ecran:
#include <iostream>
using namespace std;
int n , x[100];
void afisare(int k){
for(int i = 1 ; i <= k ; i ++)
cout << x[i] << " ";
cout << endl;
}
bool OK(int k){
for(int i = 1 ; i < k ; i ++)
if(x[i] == x[k])
return 0;
return 1;
}
void back()
{
int k = 1;
x[1] = 0;
while(k > 0)
{
bool gasit = false;
do{
x[k] ++;
if(x[k] <= n && OK(k))
gasit = true;
}
while(! gasit && x[k ] <= n);
if(! gasit)
k --;
else
if(k < n)
{
k ++;
x[k] = 0;
}
else
afisare(k);
}
}
int main(){
cin >> n;
back();
return 0;
}

O variantă (puțin) mai bună
Algoritmul de generarea a permutărilor este unul exponențial, deci lent. Totuși, poate fi ușor îmbunățit în ceea ce privește verificarea condițiilor interne. Acestea cer ca valoarea curentă a lui x[k] (elementul care se generează) să nu se repete. În varianta anterioară am parcurs elementele care îl preced și le-am comparat cu x[k].
Această parcurgere poate fi evitată dacă folosim un vector caracteristic, uz[], cu următorul înțeles:
\(uz[v] = \begin{cases}
1& \text{dacă valoarea } v \text{ a fost plasată deja în vectorul soluție},\\
0& \text{dacă valoarea } v \text{ nu a fost plasată încă în vectorul soluție}
\end{cases} \)
Următoarele programe folosesc această idee. Primul respectă îndeaproape schema anterioară, în timp ce al doilea este mai scurt – verificarea condițiilor interne și a celor de existență a soluției făcându-se în în funcția back(), fără a mai scrie funcții de sine stătătoare:
#include <iostream>
using namespace std;
int x[10] , n , p, uz[10];
void Afis(int k)
{
for(int j = 1 ; j <= k ; j ++)
cout << x[j] << " ";
cout << endl;
}
bool OK(int k){
return uz[x[k]] == 0;
}
bool Solutie(int k)
{
return k == n;
}
void back(int k){
for(int i = 1 ; i <= n ; ++ i)
{
x[k] = i;
if(OK(k))
{
uz[i] = 1;
if(Solutie(k))
Afis(k);
else
back(k + 1);
uz[i] = 0;
}
}
}
int main(){
cin >> n;
back(1);
return 0;
}
#include <iostream>
using namespace std;
int x[10] , n , p, uz[10];
void Afis(int k)
{
for(int j = 1 ; j <= k ; j ++)
cout << x[j] << " ";
cout << endl;
}
void back(int k){
for(int i = 1 ; i <= n ; ++ i)
if(uz[i] == 0)
{
x[k] = i;
uz[i] = 1;
if(k == n)
Afis(k);
else
back(k + 1);
uz[i] = 0;
}
}
int main(){
cin >> n;
back(1);
return 0;
}
Probleme propuse
Permutari Permutari1 Permutari2 SirPIE Anagrame1 PermPF Shuffle