Articole recomandate
Stars and bars
Stars and bars (Stele și bare) este o metodă de rezolvare a unor probleme de combinatorică. Se poate folosi când trebuie să determinăm numărul de modalități de a grupa un număr dat de obiecte identice.
Teoremă: Numărul de a variante de a plasa n obiecte identice în k cutii este egal cu: \( C_{n+k-1}^{k-1} \).
Demonstrația implică separarea celor n obiecte (stele) în k cutii prin k-1 bare – de unde și numele. De exemplu, configurația următoare are n=7 stele și k=4 cutii: \( \star \vert \star \star \vert \vert \star \star \star \star \) și corespunde următoarei situații:
- prima cutie conține un obiect
- a doua cutie conține două obiecte
- a treia cutie nu conține niciun obiect
- a patra cutie conține patru obiecte
Configurația este echivalentă cu următoarea configurație de biți: 0100110000, în care bitul 1 corespunde obiectului, \( \star \), iar 1 corespunde barei, \( \vert \). Toate configurațiile convenabile au n-k+1 biți, dintre care n au valoarea 0 și k-1 au valoarea 1 și corespund submulțimilor cu k-1 elemente ale unei mulțimi cu n+k-1 elemente.
Astfel, numărul lor este \( C_{n+k-1}^{k-1} \).
Consecință Ecuația \(x_1 + x_2 + x_3 + \cdots + x_k = n\) are \( C_{n+k-1}^{k-1} \) soluții întregi nenegative (mai mari sau egale cu 0).
Afirmația este echivalentă cu teorema de mai sus, în care \(x_i\) fiind egal cu numărul de obiecte din cutia i.
Teoremă: Numărul de a variante de a plasa n obiecte identice în k cutii astfel încât fiecare cutie conține cel puțin un obiect este egal cu: \( C_{n-1}^{k-1} \).
Demonstrația 1: Fixăm în fiecare cutie câte un obiect. Rămân \(n – k\) obiecte care trebuie plasate în \(k\) cutii, în condițiile teoremei de mai sus. Astfel, numărul de variante este \( C_{n-k+k-1}^{k-1} = C_{n-1}^{k-1} \).
Demonstrația 2: Folosim metoda Stars and bars. Separarea obiectelor în cutii se face plasând \(k\) bare în golurile dintre obiecte. Sunt \(n-1\) goluri în care putem plasa \(k\) bare în \( C_{n-1}^{k-1} \) moduri.
 Candale Silviu (silviu)
Candale Silviu (silviu) Exponențiere rapidă
Ridicarea la putere este o operație binecunoscută, formulă uzuală fiind: $$ A^n = \prod_{i=1}^n {A} = \underbrace{A \times A \times … \times A }_{\text{de } n \text{ ori}} $$
Un algoritm care implementează această metodă va avea complexitate liniară, \(O(n)\):
int Putere(int A , int n)
{
int P = 1 ;
for(int i = 1 ; i <= n ; i ++)
P = P * A;
return P;
}
Descriere
O metodă mai bună este cea numită exponențierea rapidă , sau ridicarea la putere în timp logaritmic, complexitatea sa fiind \(O(\log_2{n})\). Ea se bazează pe următoarea formulă:
$$ A^n = \begin{cases} 1& \text{, dacă } n = 0\\ A \cdot A^{n-1}& \text{, dacă } n \text{ – impar}\\ {\left(A^{\frac{n}{2}}\right)}^2& \text{, dacă } n \text{ – par} \end{cases}$$
Exemplu
Să calculăm \(2^{25}\):
- \(2^{25} = 2 \cdot 2^{24}\), deoarece
25este impar - \(2^{24} = {(2^{12})}^2\), deoarece
24este par - \(2^{12} = {(2^{6})}^2\), deoarece
12este par - \(2^{6} = {(2^{3})}^2\), deoarece
6este par - \(2^{3} = 2 \cdot 2^{2}\), deoarece
3este impar - \(2^{2} = {(2^{1})}^2\), deoarece
2este par - \(2^{1} = 2 \cdot 2^{0}\), deoarece
1este impar - \(2^{0} = 1\)
Atunci în ordine inversă:
- \(2^{1} = 2 \cdot 1 = 2\)
- \(2^{2} = {2}^2 = 4\)
- \(2^{3} = 2 \cdot 4 = 8\)
- \(2^{6} = {8}^2 = 64\)
- \(2^{12} = {64}^2 = 4096\)
- \(2^{24} = {4096}^2 = 16777216\)
- \(2^{25} = 2 \cdot 16777216 = 33554432\)
Constatăm că numărul înmulțirilor efectuate este mult mai mic decât în cazul primei metode.
Implementare recursivă
Implementarea recursivă este directă:
int Putere(int A , int n)
{
if(n == 0)
return 1;
if(n % 2 == 1)
return A * Putere(A , n - 1);
int P = Putere(A , n / 2);
return P * P;
}
Implementare iterativă
Să considerăm \(A^{25}\). Să-l scriem pe \(25\) ca sumă de puteri ale lui \(2\) (orice număr natural poate fi scris ca sumă de puteri ale lui \(2\) într-un singur mod): \(25 = 1 + 8 + 16\).
Atunci \( A^{25} = A^{1 + 8 + 16} = A^1 \cdot A^8 \cdot A^{16} = \underbrace{{(A^1)}^1}_{=A^1} \cdot \underbrace{{(A^2)}^0}_{=1} \cdot \underbrace{{(A^4)}^0}_{=1} \cdot \underbrace{{(A^8)}^1}_{=A^8} \cdot \underbrace{{(A^{16})}^1}_{=A^{16}}\). Observăm că exponenții \(0\) și \(1\) sunt cifrele reprezentării în baza \(2\) a lui \(25\).
Se figurează următoarea idee, pentru a determina An:
- vom determina un produs
P, format din factori de formaA1,A2,A4,A8, … - determinăm cifrele reprezentării în baza
2a luin, începând cu cea mai nesemnificativă:- dacă cifra curentă este
1, înmulțim peAlaP,P = P * A; - înmulțim pe
Acu el însuși,A = A * A;, obținând următoarea putere din șirul de mai sus
- dacă cifra curentă este
Implementare C++:
int Putere(int A , int n)
{
int P = 1;
while(n)
{
if(n % 2 == 1)
P = P * A;
A = A * A;
n /= 2;
}
return P;
}
altă variantă, care folosește operațiile pe biți:
int Putere(int A , int n)
{
int P = 1;
for(int k = 1 ; k <= n ; k <<= 1)
{
if((n & k))
P *= A;
A = A * A;
}
return P;
}
Observații
- ridicarea la putere rapidă poate fi folosită și pentru:
- operații modulo (determinarea restului împărțirii rezultatului la o valoare dată)
- numere mari
- ridicarea la putere a matricelor
- ridicarea la putere a polinoamelor
Aritmetică modulară
În numeroase probleme de informatică se cere determinarea restului împărțirii unui anumit număr (de regulă rezultat ale unui calcul) la o valoare dată, N. De cele mai multe ori numărul nu poate fi determinat direct, valoarea sa fiind prea mare. În aceste situații intervine aritmetica modulară, în care restul cerut se determină facând operații cu resturi la împărțirea cu N a unor rezultate parțiale.
Fie \( N > 1\) un număr natural și două numere întregi \(a\) și \(b\). Spunem că \(a\) și \(b\) sunt congruente modulo \(N\) , \( a \equiv b \mod N \) dacă \( N \vert (a-b) \). Echivalent, dacă \(a\) și \(b\) dau același rest la împărțirea cu \(N\).
Adunarea și înmulțirea
Avem următoarele reguli – spunem că congruența modulo N este compatibilă cu adunarea și înmulțirea numerelor întregi :
- Dacă \( a \equiv x \mod N \) și \( b \equiv y \mod N \), atunci \( a + b \equiv x + y \mod N \).
- Dacă \( a \equiv x \mod N \) și \( b \equiv y \mod N \), atunci \( a \cdot b \equiv x \cdot y \mod N \).
Consecințe (C/C++):
- având două numere naturale
a,b, iarN > 1unu număr natural:- restul împărțirii sumei la
Neste(a + b) % N = (a % N + b % N) % N - restul împărțirii produsului la
Neste(a * b) % N = ((a % N) * (b % N)) % N
- restul împărțirii sumei la
- având
nnumere naturaleA[1],A[2], …,A[n], restul împărțirii laNa produsului lor se determină astfel:
int P = 1;
for(int i =1 ; i <= n ; i ++)
P = (P * A[i]) % N;
- pentru a calcula restul împărțirii la
Na luiN!–Nfactorial:
int P = 1;
for(int i =1 ; i <= N ; i ++)
P = (P * i) % N;
Scăderea
Fie numerele naturale a ≥ b și N>1. Deși congruența modulo N este compatibilă cu operația de scădere, expresia (a-b)%N = (a%N-b%N)%N nu este întotdeauna corectă.
Mai precis, chiar dacă a > b, deci (a-b)%N≥0, expresia (a%N-b%N) și deci (a%N-b%N)%N poate fi negativă. Situatia poate fi rezolvată ușor, adunând la X=(a%N-b%N)%N valoarea N, astfel X nemaifiind negativ.
Exemplu: Fie n m, două numere naturale, 1 ≤ n ≤ m ≤ 1000. Determinați restul împărțirii lui m!-n! la 1009.
Rezolvare: Fie N = 1009. Deoarece numere sunt mari, nu putem calcula factorialele. Vom calcula A = m! % N, B= n! % N, apoi X = (A-B)%N. Dacă X este negativ, vom aduna la X valoarea N, acesta fiind și rezultatul.
Următoarea secvență C++ implementează ideea de mai sus:
int n , m;
const int N = 1009;
cin >> n >> m; // n <= m
int A = 1, B = 1;
for(int i = 1 ; i <= m ; i ++)
A = (A * i) % N;
for(int i = 1 ; i <= n ; i ++)
B = (B * i) % N;
int X = A - B;
if(X < 0)
X += N;
cout << X;
Împărțirea. Inversul modular
Congruența modulo N nu este compatibilă cu împărțirea. Consecința este că (B/A) % N != ((B % N)/(A % N)) % N. Pentru a determina rezultatul modulo N al unor expresii în care intervin împărțiri vom folosi inversul modular.
Acesta permite transformarea expresiei B/A % N într-o înmulțire și poate fi determinat numai dacă numerele A și N sunt prime între ele.
Mai precis, dacă 1 ≤ A < N, inversul lui A modulo N este un număr natural 1 ≤ A-1 < N cu proprietatea că \( A \cdot A^{-1} \equiv 1 \mod N \). Atunci (B/A) % N = (B * A-1) % N = ((B%N)*(A-1%N))%N.
Există mai multe modalități de a determina inversul modular. În cele ce urmează vom nota inversul modular al lui A cu I.
O primă variantă este să analizăm fiecare număr k cuprins între 1 și N-1. Dacă A * k % N este 1, atunci I=k. Complexitatea este \(O(n)\).
Aplicând teorema lui Euler, \(A^{\varphi(N)} \equiv 1 (\mod N)\), unde \(\varphi(N)\) este indicatorul lui Euler. Atunci \(A \cdot A^{\varphi(N)-1} \equiv 1 (\mod N)\), deci \(I=A^{\varphi(N)-1} \mod N\). Acest rezultat poate fi determinat folosind exponențierea rapidă cu complexitatea \(O(\log_{2}N)\). Putem calcula indicatorul lui Euler cu complexitatea \(O(\sqrt{N})\), deci complexitatea determinării inversului modular devine \(O(\log_{2}N \cdot \sqrt{N})\).
Dacă N este prim, atunci \(\varphi(N) = N – 1\), deci \( I = A ^{N-2} \mod N\). Pentru determinare folosim exponențierea rapidă.
Cea mai eficientă metodă de a determina inversul modular folosește algoritmul lui Euclid extins, pentru A și N. Conform acestuia, există X și Y astfel încât A*X + N*Y = 1, deoarece 1=cmmdc(A,N), A și N fiind prime între ele. Trecând la operațiile modulo N, obținem \(A \cdot X \equiv 1 \mod N\), deoarece \(N \cdot Y \equiv 1 \mod N\). De aici rezultă că inversul modular al lui A modulo N este chiar X. Dacă X determinat astfel este negativ, îl vom mări cu N până când devine pozitiv.
Următoarea secvență C++ determină inversul modular al lui A, modulo N:
void euclid(int a , int b ,int & x ,int & y)
{
if(b == 0)
{
x = 1, y = 1;
}
else
{
int x1 , y1;
euclid(b , a % b , x1 , y1);
x = y1;
y = x1 - a / b * y1;
}
}
int main()
{
int A = 9, N = 11; // prime intre ele, 1 <= A < N
int X , Y;
euclid(A, N , X ,Y);
while(X < 0)
X += N;
cout << X; // 5
return 0;
}
Inversul modular poate fi folosit, de exemplu pentru a calcula \(C_n^k\) modulo P, unde P este un număr prim.
Algoritmul lui Euclid extins. Invers modular
Algoritmul lui Euclid pentru determinarea celui mai mare divizor comun a două numere naturale are următoarea consecință: pentru două numere naturale nenule \(a\), \(b\) există numerele întregi \(x\), \(y\) astfel încât \(a \cdot x + b \cdot y = d\), unde \( d=(a,b)\) este cel mai mare divizor comun al lui \(a\) și \(b\).
Algoritmul lui Euclid
Algoritmul lui Euclid se bazează pe următoarea formulă:
\( (a,b) = \begin{cases} a& \text{dacă } b = 0\\ (b,r)& \text{dacă } b \neq 0 \end{cases} \), unde \(r\) este restul împărțirii lui \(a\) la \(b\).
Analizăm cazul \(b \neq 0\). Fie \( d=(a,b)\) Conform teoremei împărțiri cu rest, există numele naturale \(c\) și \(r\), astfel încât \( a = b \cdot c + r \), unde \( 0 \leqslant r < b\).
Dacă \( d \vert a\) și \( d \vert b \) atunc \(d \vert (a-b \cdot c)\), adică \( d \vert r\). Să presupunem că există un număr \(n > d\), astfel încât \(n = (b,r)\). Atunci \( n \vert b \) și \( n \vert r \), deci \( b \vert (b \cdot c + r) \), adică \( n \vert a \). Astfel, \( n \) este divizor comun al lui \(a\) și \(b\), dar \(d\) este cel mai mare divizor comun al lui \(a\) și \(b\) – contradicție.
Următoarea funcție recursivă implementează algoritmul lui Euclid și întoarce rezultatul printr-un parametru de ieșire:
void euclid(int a , int b ,int & d)
{
if(b == 0)
d = a;
else
euclid(b , a % b , d);
}
Algoritmul extins
Pentru a determina numere \(x\), \(y\) de mai sus, vom extinde funcția de mai sus, adăugându-i parametrii de ieșire x și y:
void euclid(int a , int b ,int & d, int & x ,int & y);
Determinarea valorilor lui x și y se va face astfel:
- dacă
beste nul, atuncid = ași deoarecea * 1 + 0 * y = a, deducem căx=1, iarypoate lua orice valoare, de exempluy=0; - dacă
beste nenul, se determină în urma autoapeluluix1șiy1astfel încâtb*x1+r*y1=d, under = a % b. Pe de altă parte,a = b * c + r, undec = a / b, decir = a - b * c. Înlocuind, obținem:b * x1 + (a - b * c) * y1 = db * x1 + a * y1 - b * c * y1 = da * y1 + b * (x1 - c * y1) = d, undec = a / b– câtul impărțiriia * y1 + b * (x1 - a / b * y1) = d- deci
x = y1șiy = x1 - a / b * y1
Funcția următoare implementează algoritmul descris mai sus:
void euclid(int a , int b ,int & d, int & x ,int & y)
{
if(b == 0)
{
d = a;
x = 1, y = 1;
}
else
{
int x1 , y1;
euclid(b , a % b , d, x1 , y1);
x = y1;
y = x1 - a / b * y1;
}
}
Invers modular
Operația B/A nu poate fi realizată modulo N astfel: (B/A) % N != ((A % N)/(B % N)) % N – ușor de verificat pentru exemple concrete – deși relațiile similare au loc pentru adunare și înmulțire.
Restul împărțirii la N a lui B/A poate fi determinat, dacă A și N sunt prime între ele, prin intermediul inversului modular – dacă A și N nu sunt prime între ele, inversul modular nu există.
Mai precis, dacă 1 ≤ A < N, inversul lui A modulo N este un număr natural 1 ≤ A-1 < N cu proprietatea că \( A \cdot A^{-1} \equiv 1 \mod N \). Atunci (B/A) % N = (B * A-1) % N = ((B%N)*(A-1%N))%N.
Pentru a determina inversul modular, folosim algoritmul lui Euclid extins. Mai precis, conform algoritmului, există X și Y astfel încât A*X + N*Y = 1, deoarece 1=cmmdc(A,N), A și N fiind prime între ele. Trecând la operațiile modulo N, obtinem \(A \cdot X \equiv 1 \mod N\), deoarece \(N \cdot Y \equiv 0 \mod N\). De aici rezultă că inversul modular al lui A modulo N este chiar X. Dacă X determinat astfel este negativ, îl vom mări cu N până când devine pozitiv.
Următoarea secvență C++ determină inversul modular al lui A, modulo N:
void euclid(int a , int b ,int & x ,int & y)
{
if(b == 0)
{
x = 1, y = 1;
}
else
{
int x1 , y1;
euclid(b , a % b , x1 , y1);
x = y1;
y = x1 - a / b * y1;
}
}
int main()
{
int A = 9, N = 11; // prime intre ele, 1 <= A < N
int X , Y;
euclid(A, N , X ,Y);
while(X < 0)
X += N;
cout << X; // 5
return 0;
}
Inversul modular poate fi folosit, de exemplu pentru a calcula \(C_n^k\) modulo P, unde P este un număr prim.
Elemente de combinatorică
Analiza combinatorică este un domeniu al matematicii care studiază modalitățile de numărare ale elementelor mulțimilor finite, precum și de alegere și aranjare a lor. Numeroase concepte specifice acestui domeniu intervin și în probleme de algoritmică.
Produsul cartezian
Fie \( n \in \mathbb{N} \) și mulțimile \(A_1\), \(A_2\)., …, \(A_n\). Produsul cartezian \( A_1 \times A_2 \times … \times A_n \) este mulțimea \(n\)-uplurilor \(\left(x_1,x_2,…,x_n\right)\) cu proprietatea că \(x_1 \in A_1\), \(x_2 \in A_2\), …, \(x_n \in A_n\).
Regula produsului: Dacă mulțimile \(A_1\), \(A_2\)., …, \(A_n\) au respectiv \(k_1\), \(k_2\)., …, \(k_n\) atunci numărul de elemente al produsului cartezian \( A_1 \times A_2 \times … \times A_n \) este \(k_1 \cdot k_2 \cdot … \cdot k_n\).
Submulțimile unei multimi
Fie \(A\) o mulțimi cu n elemente. Atunci ea are \(2^n\) submulțimi:
Exemplu: Mulțimea \(A={1,2,3}\) are \(2^3 = 8\) submulțimi:
- \( \emptyset \)
- \(\left\{1\right\}\), \(\left\{ 2 \right\}\), \(\left\{ 3 \right\}\)
- \(\left\{1,2\right\}\), \(\left\{1,3\right\}\), \(\left\{2,3\right\}\)
- \(\left\{1,2,3\right\}\)
Permutări
Se numește permutare o corespondență biunivocă (bijecție) între o mulțime finită și ea însăși.
Altfel spus, se numește permutare a unei mulțimi finite o aranjare a elementelor sale într-o anumită ordine.
Exemplu: permutările mulțimii {1,2,3} sunt: (1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,1,2) și (3,2,1). Într-o altă reprezentare, acestea sunt:
\( \begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 1 & 3 & 2 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 2 & 1 & 3 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 2 & 3 & 1 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 3 & 1 & 2 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 3 & 2 & 1 \end{pmatrix} \)
Dacă \( \sigma = \begin{pmatrix} 1 & 2 & 3 \\ 3 & 1 & 2 \end{pmatrix} \), atunci \( \sigma(1) = 3 \), \( \sigma(2) = 1 \) și \( \sigma(3) = 2 \).
Numărul de permutări al unei mulțimi cu \(n\) elemente este \( P_n = n! = 1 \cdot 2 \cdot \cdot … \cdot n\). Acest articol conține mai multe despre factorialul unui număr.
Numărul permutărilor unei mulțimi crește foarte repede. Pentru valori mici ale lui n, numărul permutărilor depășește domeniul de valori al datelor întregi, fiind necesară implementarea operațiilor pe numere mari.
Permutări cu repetiție
Considerăm un set de \(n\) obiecte de \(k\) tipuri. Avem \(n_1\) obiecte de tipul 1, \(n_2\) obiected e tipul 2, …, \(n_k\) obiecte de tipul k și \(n_1 + n_2 + … + n_k = n\). Numărul de permutări distincte ale celor n obiecte este:
$$ P_R(n) = \frac{n ! }{n_1 ! \cdot n_2 ! \cdot … \cdot n_k !} $$
Exemplu: Numărul de anagrame distincte ale cuvântului ABABA este:
$$ P_R(2+3) = \frac{(2+3) ! }{ 2 ! \cdot 3 ! } = \frac{1 \cdot 2 \cdot 3 \cdot 4 \cdot 5}{1 \cdot 2 \cdot 1 \cdot 2 \cdot 3} = 10 $$
Acestea sunt: AAABB, AABAB, AABBA, ABAAB, ABABA, ABBAA, BAAAB, BAABA, BABAA, BBAAA.
Aranjamente
Dacă A este o mulțime cu n elemente, submulțimile ordonate cu k elemente ale lui A, 0 ≤ k ≤ n se numesc aranjamente a n elemente luate câte k.
Numărul de aranjamente de \(n\) luate câte \(k\) se notează \( A_{n}^{k} = n \cdot (n-1) \cdot (n-2) \cdot … \cdot (n-k+1) = \frac{ n! }{(n-k)!} \).
La fel ca în cazul permutărilor, pentru determinarea numărului de aranjamente poate fi necesară implementarea operațiilor pe numere mari.
Combinări
Pentru o mulțime dată o combinare reprezintă o modalitate de alegere a unor elemente, fără a ține cont de ordinea lor. Se numesc combinări de k elemente submulțimile cu k elemente ale mulțimii, presupuse cu n elemente. Numărul de asemenea submulțimi se numește combinări de n luate câte k și se notează \(C_n^k\).
Formule:
- \(C_n^k = \frac{A_n^k}{P_k}\)
- \(C_n^k = \frac{n \cdot (n-1) \cdot … \cdot (n-k+1)}{1 \cdot 2 \cdot … \cdot k}\)
- \(C_n^k = \frac{n!}{k!\cdot {(n-k)!}} \)
- \(C_n^k= \begin{cases}
1& \text{dacă } k = 0,\\
\frac{n – k + 1}{k} \cdot { C_n^k } & \text{altfel}.
\end{cases} \) - \(C_n^k= \begin{cases}
1& \text{dacă } n = k \text{ sau } k = 0,\\
{ C_{n-1}^{k-1} } + { C_{n-1}^k } & \text{altfel}.
\end{cases} \); această formulă se regăsește în Triunghiul lui Pascal
Numerele lui Catalan
Termenul general al acestui șir este:
$$ C_n = C_{2n}^{n} – C_{2n}^{n+1} = \frac{1}{n+1}\cdot C_{2n}^{n} = \prod _{k=2}^{n} \frac{n+k}{k}, \text{pentru } n ≥ 0 $$
O formulă recursivă:
$$ C_{n+1} = \sum_{i=0}^{n}{C_i \cdot C_{n-i}} $$
Pentru \(n=0,1,2,3,…\) numere Catalan sunt: \( 1, 1, 2, 5, 14, 42, 132, 429, 1430, 4862, … \).
Există numeroase probleme care au ca rezultat numerele lui Catalan. Amintim:
- \(C_n\) este egal cu numărul de șiruri de
nparanteze deschise șinparanteze închise care se închid corect. Pentrun=3, avem \(C_3 = 5\) variante:((())),(())(),()(()),()()()și(()()). - numărul de cuvinte Dyck de lungime
2*n: formate dinncaractereXșincaractereYși în orice prefix numărul deXeste mai mare sau egal cu numărul deY. Pentrun=3:XXXYYY,XXYYXY,XYXXYY,XYXYXY,XXYXYY. - numărul de șiruri formate din
nde1șinde-1astfel încât toate sumele parțiale să fie nenegative. - \(C_n\) reprezintă numărul de modalități de a paranteza o expresie formată din
n+1operanzi ai unei operatii asociative:((ab)c)d,(a(bc))d,(ab)(cd),a((bc)d),a(b(cd)). - \(C_n\) reprezintă numărul de modalităti de a desena “șiruri de munți” cu
nlinii crescătoare șinlinii descrescătoare. Munții încep și se termină la același nivel și nu coboară sub acel nivel:
/\
/\ /\ /\/\ / \
/\/\/\ / \/\ /\/ \ / \ / \
- numărul de drumuri laticiale de la punctul
(0,0)la(2*n,0)cu pași din{(1,1),(1,-1)care nu coboară sub axaOx. - \(C_n\) este numărul de modalități de a triangula un poligon cu
n+2laturi:

- \(C_n\) este umărul de drumuri laticiale de la
(0,0)la(n,n)cu pași din{(0,1),(1,0)}care nu depășesc prima diagonală \(y = x\). Următoarea imagine conține drumurile pentrun=4:

- numărul de siruri \( 1 \leqslant a_1 \leqslant a_2 \leqslant … \leqslant a_n \) cu proprietatea că \(a_k \leqslant k \) este \(C_n\).
- \(C_n\) numărul de modalități de a acoperi o scară cu
ntrepte folosindndreptunghiuri. Pentrun=4:

- pe un cerc sunt
2*npuncte. Numărul posibilități de a desenancoarde care nu se intersectează este \(C_n\).
Alte probleme care au care rezultat numărul lui Catalan sunt pe Wikipedia sau în documentul Exercises on Catalan and Related Numbers, Cambridge University Press, Richard P_ Stanley, June 1998.
Partițiile unei mulțimi
Fie \(A={a_1, a_2, …, a_n}\) o mulțime (finită). Se numește partiție a mulțimii \(A\) o familie de submulțimi \(A_1, A_2, …, A_k\) ale lui \(A\) cu proprietățile:
- \( A_i \subseteq A \), \( \forall i = \overline{1,k} \)
- \( A_1 \cup A_2 \cup … \cup A_k = A \)
- \( A_i\cap A_j = \emptyset \), \( \forall i\neq j \)
De exemplu, \(A={1,2,3}\) are următoarele partiții:
- \({1,2,3}\)
- \({1,2},{3}\), \({1,3},{2}\), \({1}, {2,3}\)
- \({1},{2},{3}\)
Numărul de partiții cu \(k\) submulțimi ale unei mulțimi cu \(n\) elemente se numește numărul lui Stirling de speța a doua, notat \(S(n,k)\). El respectă următoarea relație de recurență:
$$ \begin{cases} S(0,0) = 1\\
S(0,n) = S(n,0) = 0\\
S(n+1,k) = k \cdot S(n,k) + S(n,k-1) & \text{pentru } k > 0 \end{cases}
$$
Numerele Strirling de speța a doua pe Wikipedia
Numărul total de partiții ale unei mulțimi cu \(n\) elemente este numărul lui Bell: $$B_n = \sum_{k=0}^n S(n,k)$$
Începând cu \(B_0 = B_1 = 1\), primele numere Bell sunt: \(1, 1, 2, 5, 15, 52, 203, 877, 4140, … \).
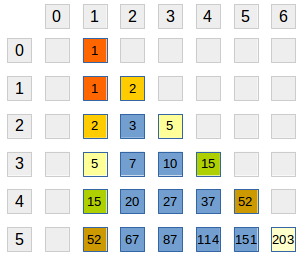
Numerele Bell pot fi construite cu ajutorul așa-numitului triunghi Bell. Vom construi (parțial) un tablou A[][]:
A[0][1] = 1- primul element de pe liniile următoare este egal cu ultimul de pe linia precedentă:
A[i][1] = A[i-1][i] - celelalte elemente ale fiecărei linii sunt egale cu suma celor după elemnte din stânga (linia curentă și linia precedentă):
A[i][j] = A[i][j-1] + A[i-1][j-1], pentruj=2,..., i+1 - primul elelemt de pe fiecare linie este numărul Bell corespunzător:
Bn=A[n][1].
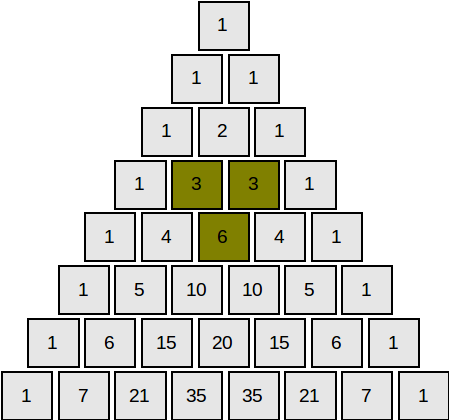
Triunghiul lui Pascal
Triunghiul lui Pascal este un tablou triunghiular cu numere naturale, în care fiecare element aflat pe laturile triunghiului are valoarea 1, iar celelalte elemente sunt egale cu suma celor două elemente vecine, situate pe linia de deasupra.
Proprietăți
Putem rearanja elementele tabloului astfel:
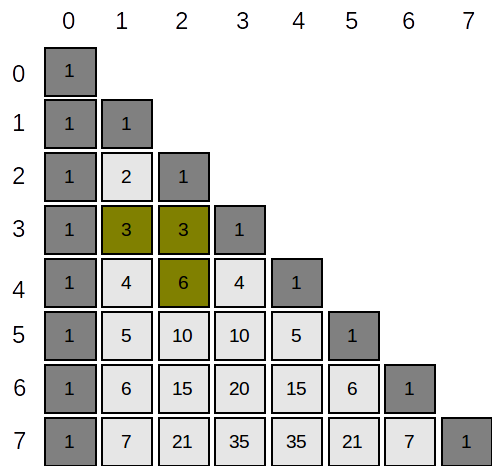
Considerând liniile și coloanele numerotate ca mai sus atunci: \( A_{i,j} = \begin{cases}
1& \text{dacă } i = j \text{ sau } j = 0,\\
A_{i-1,j-1 } + A_{i-1, j} & \text{altfel}.
\end{cases} \). De fapt, această relație este cunoscută în calculul combinărilor: \( {C^{k}_{n}} = \begin{cases}
1& \text{dacă } n = k \text{ sau } k = 0,\\
{ C^{k-1}_{n-1} } + { C^{k}_{n-1} } & \text{altfel}.
\end{cases} \), unde \(C^{k}_{n}\) înseamnă “combinări de n luate câte k”. De fapt, un element \(A_{i,j}\) al tabloului de mai sus este egal cu \( {C^{j}_{i}} \).
Elementele de pe linia n sunt coeficienți binomiali ai dezvoltării \( (a+b)^n = C^{0}_{n} \cdot a^n + C^{1}_{n} \cdot a^{n-1} \cdot b^1 + C^{2}_{n} \cdot a^{n-2} \cdot b^2 + \cdots + C^{k}_{n} \cdot a^{n-k} \cdot b^k + \cdots + C^{n-1}_{n} \cdot a^{1} \cdot b^{n-1} + C^{n}_{n} \cdot b^{n} \) – binomul lui Newton.
Suma elementelor de pe linia n este egală cu 2n: \( {C^{0}_{n}} + {C^{1}_{n}} + {C^{2}_{n}} + \cdots + {C^{k}_{n}} + \cdots + {C^{n}_{n}} = 2^n \).

Problemă
Se citește un număr natural n. Afișați linia n din triunghiul lui Pascal.
Soluție cu combinări
O primă soluție constă în calcularea valorii \( C^{k}_{n} \) pentru fiecare \( k \in \left\{0, 1, 2, \cdots , \ n \right\} \).
#include <iostream>
using namespace std;
int comb(int n , int k)
{
int p = 1;
for(int i = 1 ; i <= k ; i ++)
p = p * (n-i+1) / i;
return p;
}
int main()
{
int n;
cin >> n;
for(int i = 0 ; i <= n ; i ++)
cout << comb(n,i) << " ";
return 0;
}
O îmbunătățire a variantei de mai sus este:
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int p = 1;
cout << "1 ";
for(int i = 1 ; i <= n ; i ++)
{
p = p * (n-i+1) / i;
cout << p << " ";
}
return 0;
}
Soluție cu matrice
În soluția următoare aplicăm formula \( A_{i,j} = A_{i-1,j-1 } + A_{i-1, j} \), folosind un tablou unidimensional:
#include <iostream>
using namespace std;
int main()
{
int n, A[31][31];
cin >> n;
for(int i = 0 ; i <= n ; i ++)
{
A[i][0] = A[i][i] = 1;
for(int j = 1 ; j < i ; j ++)
A[i][j] = A[i-1][j-1] + A[i-1][j];
}
for(int j = 0 ; j <= n ; j ++)
cout << A[n][j] << " ";
return 0;
}
Soluție cu doi vectori
Soluția de mai sus poate fi îmbunătățită, observând că pentru a calcula linia curentă folosim doar linia precedentă. Vom folosi doar doi vectori, unul pentru linia curentă, celălalt pentru linia precedentă:
#include <iostream>
using namespace std;
int main()
{
int n, v[31],u[31];
cin >> n;
v[0] = 0;
for(int i = 1 ; i <= n ; i ++)
{
u[0] = u[i] = 1;
for(int j = 1 ; j < i ; j ++)
u[j] = v[j-1] + v[j];
for(int j = 0 ; j <= i ; j ++)
v[j] = u[j];
}
for(int j = 0 ; j <= n ; j ++)
cout << v[j] << " ";
return 0;
}
Soluție cu doi vectori și doi pointeri
În soluția de mai sus putem evita copierea elementelor din u în v, folosind doi pointeri suplimentari. Aceștia vor memora adresa de început a celor două tablouri, iar copierea elementelor este înlocuită de interschimbarea valorilor celor doi pointeri:
#include <iostream>
using namespace std;
int main()
{
int n, A[31], B[31];
int * u = A, * v = B;
cin >> n;
v[0] = 0;
for(int i = 1 ; i <= n ; i ++)
{
u[0] = u[i] = 1;
for(int j = 1 ; j < i ; j ++)
u[j] = v[j-1] + v[j];
swap(u,v);
}
for(int j = 0 ; j <= n ; j ++)
cout << v[j] << " ";
return 0;
}
Soluție cu un singur vector
Putem folosi un singur vector. Acesta conține linia anterioară și se modifică pas cu pas, pentru a deveni linia curentă a triunghiului:
#include <iostream>
using namespace std;
int main()
{
int n, v[31];
cin >> n;
v[0] = 0;
for(int i = 1 ; i <= n ; i ++)
{
v[i] = 1;
for(int j = i - 1 ; j > 0 ; j --)
v[j] = v[j] + v[j-1];
v[0] = 1;
}
for(int j = 0 ; j <= n ; j ++)
cout << v[j] << " ";
return 0;
}